How to deadlock Tokio application in Rust with just a single mutex
Battlefield story of how we managed to deadlock Tokio program with just a single mutex

Rust has a great support for asynchronous programming based on futures and async/await. Futures are part of the core Rust language but they require a runtime to execute. Tokio is probably the most popular runtime at the moment in the Rust community. We at Turso use it too and we recently run into a very interesting problem related to Tokio. We discovered a deadlock in a code that was using just a single mutex. Thanks to the hard work of Nikita Sivukhin we managed to create a minimal reproducer and fix the issue. The code below deadlocks.
/* Cargo.toml
[package]
name = "tokio-deadlock"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1.40.0", features = ["full"] }
*/
async fn sleepy_task() {
tokio::time::sleep(Duration::from_millis(100)).await;
}
#[tokio::main]
async fn main() {
let mutex = std::sync::Arc::new(std::sync::Mutex::new(()));
let async_task = tokio::spawn({
let mutex = mutex.clone();
async move {
loop {
eprintln!("async thread start");
tokio::time::sleep(Duration::from_millis(100)).await;
let guard = mutex.lock().unwrap();
drop(guard);
eprintln!("async thread end");
}
}
});
let blocking_task = tokio::task::spawn_blocking({
let mutex = mutex.clone();
move || loop {
eprintln!("blocking thread start");
let guard = mutex.lock().unwrap();
tokio::runtime::Handle::current().block_on(sleepy_task());
drop(guard);
eprintln!("blocking thread end");
}
});
for future in vec![async_task, blocking_task] {
future.await.unwrap();
}
}
There's only one mutex in this code and it is shared between two task. One asynchronous (started with tokio::spawn) and one synchronous (started with tokio::spawn_blocking). Asynchronous task just obtains the lock and then releases it immediately but synchronous task obtains the lock and then blocks on a future while keeping this lock. This future is not using the mutex at all.
I don't have a full explanation on what is causing the deadlock but this has probably something to do with Tokio worker threads being blocked by the mutex and then the future created by sleepy_task not being able to make any progress and blocking synchronous task indefinitely.
This issue can be easily fixed by using tokio::sync::Mutex instead of std::sync::Mutex. The code below works just fine.
/* Cargo.toml
[package]
name = "tokio-deadlock"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1.40.0", features = ["full"] }
*/
async fn sleepy_task() {
tokio::time::sleep(Duration::from_millis(100)).await;
}
#[tokio::main]
async fn main() {
let mutex = std::sync::Arc::new(tokio::sync::Mutex::new(()));
let async_task = tokio::spawn({
let mutex = mutex.clone();
async move {
loop {
eprintln!("async thread start");
tokio::time::sleep(Duration::from_millis(100)).await;
let guard = mutex.lock().await;
drop(guard);
eprintln!("async thread end");
}
}
});
let blocking_task = tokio::task::spawn_blocking({
let mutex = mutex.clone();
move || loop {
eprintln!("blocking thread start");
let guard = mutex.blocking_lock();
tokio::runtime::Handle::current().block_on(sleepy_task());
drop(guard);
eprintln!("blocking thread end");
}
});
for future in vec![async_task, blocking_task] {
future.await.unwrap();
}
}
One question that can come to mind is why wasn't tokio::sync::Mutex used in the first place. Normally that would be the first intuition to use Tokio's Mutex in code based on Tokio but Tokio's documentation itself is encouraging usage of std::sync::Mutex over tokio::sync::Mutex because of the performance.
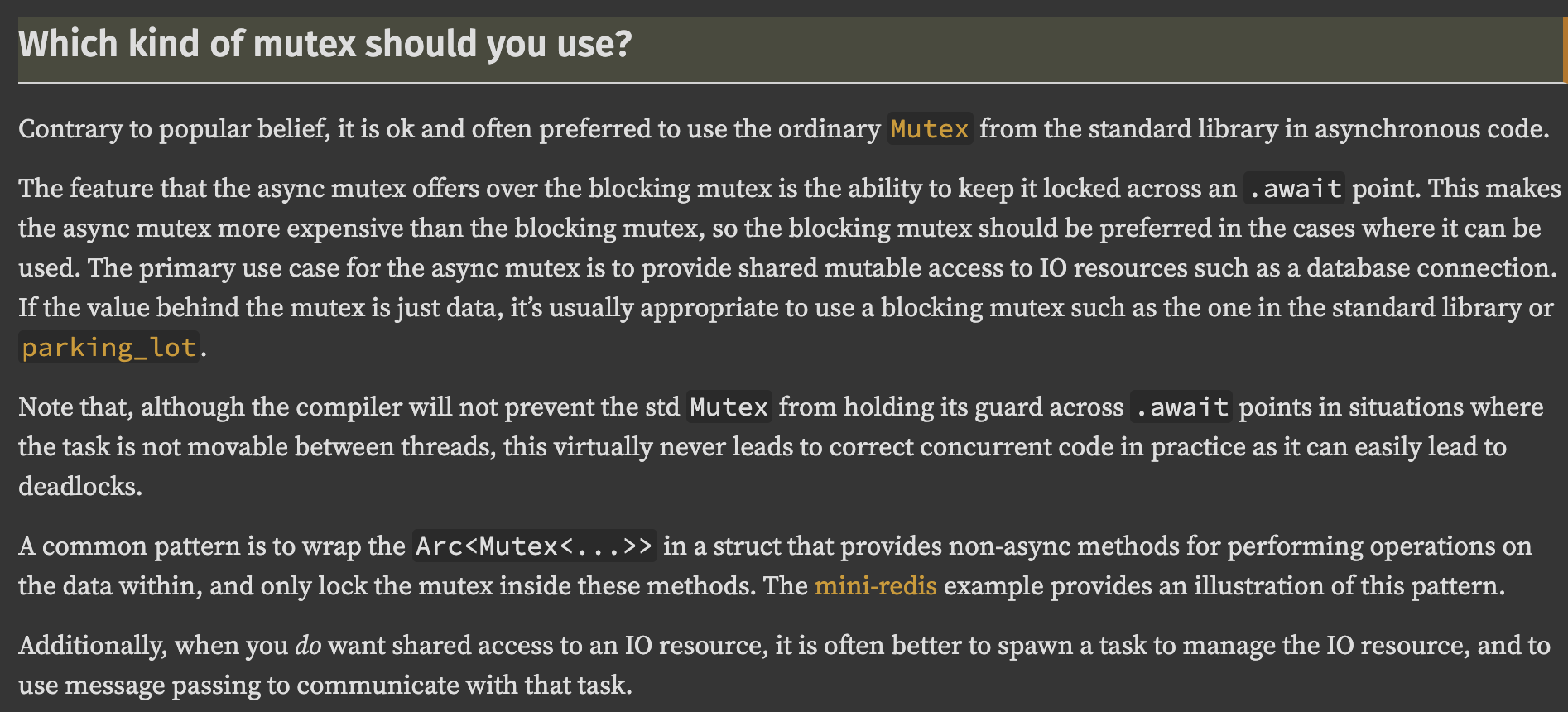
I guess in our case we're keeping the std::sync::Mutex across .await point. It's just not explicit because the synchronous task blocks on a future that might have .await points.
What's the lesson from this experience? One could be that concurrent programming is not trivial and it requires special care. Another one could be that premature optimization is the root of all evil. tokio::sync::Mutex should probably be used by default in asynchronous code based on Tokio unless it's proven to be a performance bottleneck. I find it a repeating pattern that Rust documentation encourages usage of advanced performance optimisation techniques despite them often being razor blades. A good example are atomics which are presented in many Rust examples using Ordering::Relaxed memory ordering. Memory ordering is a complicated matter and in my opinion unless you're Hans Boehm you're better off defaulting to sequential consistency memory order until the operation on the atomic variable becomes the performance bottleneck of your code.