We rewrote large parts of our API in Go using AI: we are now ready to handle one billion databases

Recently, we started hitting scalability issues with our API. In the backdrop of that, there was a mandate from our CEO: The Turso Cloud needs to be able to scale to host one billion databases in the next 12 months.
The solution? We rewrote large parts of our API in Go, using AI. Our entire API was already written in Go. But it was written in Go in a way that sucks. We have now written it in Go in a way that doesn't suck. We also got a memo from the CEO saying we had to use AI for this, so I (Avinash), was assigned to work on it and with the use of Avinash's Intelligence we could check that box too.
We will now take a deeper look at how we did it. But first, some context
#What is the Turso Cloud API?
To understand why this rewrite was necessary, let's first look at what we're actually building and why it faces such unique scalability challenges.
The Turso Cloud is a hosted database solution based on SQLite. It allows for serverless access to SQLite databases, which provides a reliable and affordable database for builders. It also enables SQLite databases to be synchronized to and from SQLite files inside your mobile devices and server infrastructure, supporting offline access and local-first applications. (Browser sync coming at some point!)
One of the most important use cases we see is the fast creation of databases programmatically—we're talking hundreds of milliseconds here. Those databases are ideal to support AI (Artificial Intelligence) agents, where every single prompt can be backed by an individual database. Those databases tend to be small, but you end up with a very large number of them. One of our customers scaled to over 2 million databases in a matter of weeks. This pattern also supports privacy-oriented use cases, where data for individual users is kept separate and isolated.
This explosive growth in database creation is exactly what led to our scalability crisis.
#Why Go?
Before diving into the technical problems, it's worth explaining our technology choices. Our full rewrite of SQLite, which is quickly gaining steam, is written in Rust. Our massively multi-tenant server that serves the SQLite databases is also written in Rust. But we decided to write our API layer—the part that handles all the platform management—in Go.
Writing our API in Go achieves two main goals:
-
Go is a very pleasant language to write services that are mostly calling other APIs and dealing with serialization and deserialization of things. It is fast, scales well, easy to deploy, and easy to write.
-
Even though we love Rust and use it extensively, Go was the right choice for our API layer. It also has the added benefit of deterring the "why not Rust?" X crowd who refuse to see value in anything else.
#Understanding the Turso Cloud API Architecture
Now that we've established the language choice, let's talk about how our API is structured, because this architecture is central to understanding our scalability challenges.
Our API is, broadly speaking, divided into two parts: the core and the proxy layer. The core is what users interact with when they're creating, deleting, or doing any management operations on databases. The proxy layer is what users interact with in every single request to their databases.
The goal of the proxy layer is to translate a database URL, like https://my-db.turso.io, to its physical location on our servers. For example, if our load balancer decides to move a database to a different physical server, that mapping has to be updated somewhere.
Both the core and the proxy have to keep a copy of the database mapping. But their requirements are very different. For the core, fast access to the database mapping isn't critical—we only need to update the mappings when databases are created, deleted, or moved. For the proxy, fast access is absolutely crucial. Any access latency gets added to every single user request.
This difference in requirements is where our problems began.
#The problem: timeouts, and excessive memory usage
When the number of databases was "small"—before agents started creating databases programmatically—our solution was straightforward. When the proxy came online, it would read all the mappings from the core service. As the core updated the mappings, it would synchronously inform the proxy about changes.
As the number of databases grew exponentially, this naive approach started breaking down in spectacular ways.
The first major issue we hit was with what we call bootstrapping the proxy—the process of reading the list of databases into the proxy when it starts up. This process started putting enormous strain on the core API. The core API had to send a payload to the proxy containing information about all databases. This payload would use a massive amount of memory, which required our API boxes to be severely overprovisioned.
Thankfully, the solution here was relatively straightforward: through streaming and pagination, we could keep the memory used by the bootstrapping process bounded. Instead of loading everything at once, we could process the data in manageable chunks.
But even after we fixed bootstrapping, the proxy itself still required way too much memory to run. Routes were kept in a large hash map, where each route was represented by this struct:
type Address struct {
App string `json:"app"`
Address string `json:"address"`
Namespace string `json:"namespace"`
}
Here's the key insight: an App is essentially the user who owns the databases. As a result, all databases owned by the same user will share the same App field. The Address is the physical location of the server hosting the database. Because of the multi-tenant nature of our offering, it's also common for many databases to point to the same server.
We were storing the same strings over and over again, millions of times.
The solution we found was to employ interning—a technique where we store strings only once, and then just store the ID of those strings whenever they're used. Go has a very handy package for this in its standard library that we used for this optimization: https://go.dev/blog/unique.
After interning, an individual route now looks like this:
type Address struct {
App unique.Handle[string] `json:"app"`
Address unique.Handle[string] `json:"address"`
Namespace string `json:"namespace"`
}
We also took the opportunity to implement some other optimizations. The most impactful was that we stopped storing the entire URL as keys for the map. For example, a common URL might look like this: database-acmeorg.aws-us-east-1.turso.io.
But since our proxies are per region, there's no need to store the aws-us-east-1.turso.io part. This yielded significant memory savings.
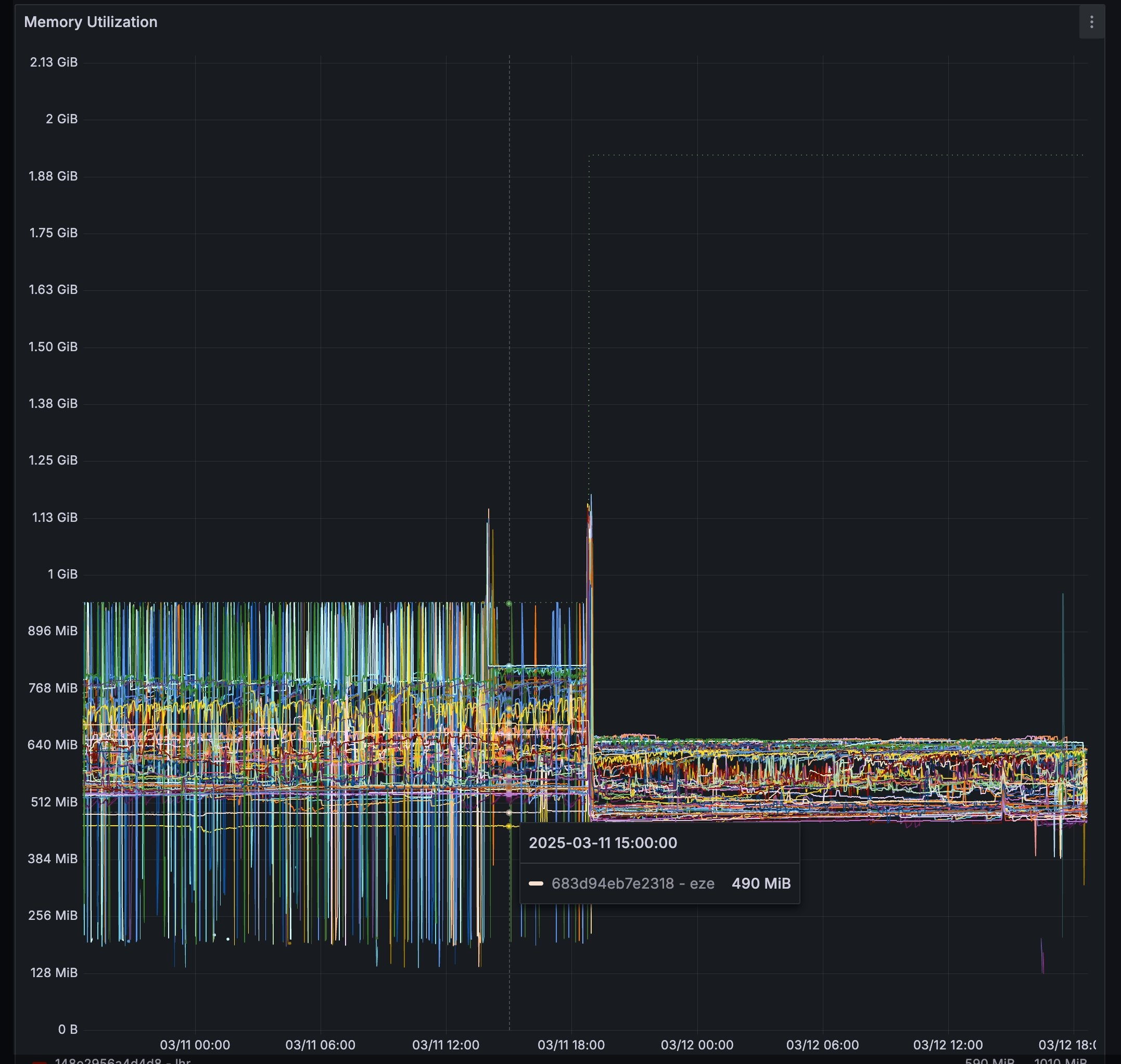
Once these changes were deployed, memory usage became not only lower, but also much more stable over time—especially during proxy restarts, which also became less frequent.
#Out with in-memory!
Despite these improvements, which were enough to temporarily let us throw money at the problem by getting larger machines, we understood that this approach wouldn't scale to the billions of databases our CEO expected us to handle.
Here's the sobering reality: with the continued demand for database creation on the Turso Cloud, we were seeing memory usage grow by 500MB per week. At this rate, even our memory optimizations would only buy us time, not solve the fundamental scalability challenge. The days of keeping everything in-memory had to be over.
Our next step was to add persistent state to the proxy layer. Once the proxy reads the initial mappings from the core API, we now store them in a SQLite database. This approach solves multiple problems at once.
First, the bootstrapping issue disappears completely. When the proxy restarts, it can read just the delta since the last fetch, rather than reloading everything from scratch.
But more importantly, having the data backed by a SQLite database allows us to move away from an in-memory map entirely. Here's the key insight: many databases exist in our system, but they're not actively used. For those inactive databases, it's perfectly acceptable to pay a small latency penalty on first access. Thanks to SQLite, even a cache miss that results in a disk read takes a few microseconds.
Instead of a hashmap that keeps everything in memory, we now use an LRU cache that fetches data from the SQLite database when there's a cache miss. This means we only keep the actively-used database mappings in memory, while the rest live safely on disk. We also track the cache miss ratio to help us tune the LRU parameters as needed.
#Future work
Our new persistence layer is actually a perfect use case for Turso's Embedded Replicas. In this model, we could replicate the SQLite database from the core API directly to the proxy, keeping them in sync as changes happen. This is, in fact, our next planned improvement.
There are other optimizations we're planning as well. For example, the name of the organization that owns the database is encoded in the URL. But in the proxy, we could use dictionary encoding to ensure that for the most active organizations, we reduce that down to an integer value.
The Turso Cloud is ready to host a billion databases. How many of them will you create? Start today with your first 500 for free.