
Turso is a rewrite of SQLite from scratch in Rust. We aim to keep full compatibility with SQLite, while adding new and exciting features like CDC, concurrent writes, encryption, among many others. It is currently in alpha, but progressing fast and getting close to a point where it can be used for production workloads.
Rewriting existing software systems is a special kind of hard. Aside from the difficulty in writing the software itself, you have to deal with behaviors of the existing system that are… at times… puzzling.
I would know: I have done it before, successfully and at scale. And yet, few things are more incredible than what I saw today. This is the story of how I found the most surprising compatibility issue I have ever seen, and how it got solved by an LLN.
#Your database is corrupted
It all started around 1 week ago when one of our engineers came up with a sad discovery: inserting more than 1GB into the database led to data corruption. The integrity checks on SQLite would fail. What made this more puzzling is that it was neither "sometimes" nor “around 1GB”. Every time we added 1GB, the very next write would lead to SQLite integrity checks failing. It could be a single 1GB blob, it could be a lot of very small byte-sized inserts. Every time the database crossed the 1GB mark, the next insert would corrupt the database.
We pride ourselves in writing the database relying heavily on Deterministic Simulation Testing. DST allows us to test decades worth of combinations in mere hours, and stress the database under the most challenging conditions. To the point that we have a challenge (https://turso.algora.io): if anyone can find a bug that leads to data corruption and improve our simulator to catch it next time, we will pay you a cash prize.
Because of our testing methodology we saw this issue with a mixture of disbelief and excitement. Where did we fail? How does the simulator have to be improved to catch these kinds of bugs next time?
After some investigation it became clear: because all of our profiles do fault injection (simulating failures, which is where most bugs hide), none of our test databases actually got to 1GB. Failures would stop it before it got there.
#Your database is not corrupted
Here is how the plot thickens: once we improved the simulator to also generate some runs without faults, so the databases would have a chance to grow, we started seeing the bug every time. In even more combinations than before, every single time it crosses 1GB, the database is corrupted. Or is it? As we kept investigating, we could not see anything wrong with those databases. Our own integrity checks showed that the databases were fine. All pages pointed to the right place. All the data was there. Everything was readable.
And yet it was corrupted. Our little Schroedinger database was both corrupted and not corrupted at the same time. And only when it crossed 1GB mark.
We spent almost a week asking ourselves: What’s so special about 1GB?
#Meet Nikita
Turso is an Open Source project with a very active developer community. But there is a company behind it which runs a Cloud service based on SQLite. The company pays some people to work on Turso full time. Amongst them, Nikita Sivukhin.
Nikita has been with us for a while, and we are still not convinced he is a real person. He could be an unreleased LLM model, or an alien intelligence from another planet. Nikita is the only one in our company that refuses to use any coding model for anything. And he keeps being the most productive person in the company.
Nikita was aware of this issue, because we all were, but this was his oncall week. So he was busy with other things. Small, inconsequential things like cutting our costs by 30%, fixing every single bug he came across, reviewing everyone else’s code and finding every single problem before it hit production, the usual Nikita stuff.
Then out of the blue, he decides to take a look at this issue.
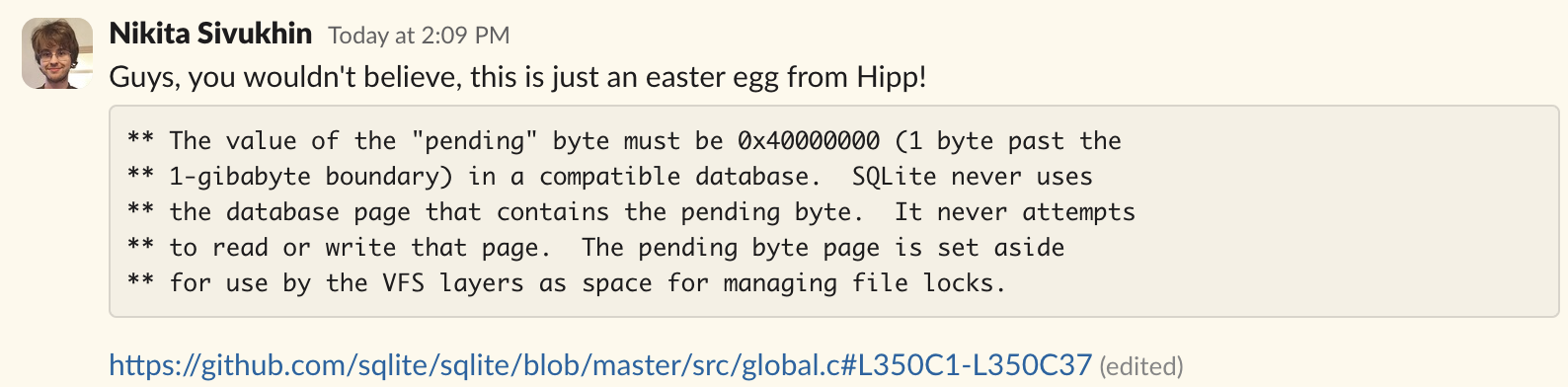
Every time a SQLite database crosses the 1GB mark, a special page is inserted into the B-Tree. That page has a special byte that only that page has. This happens for a vaguely specified reason (the comment mentions file locks, but then, how do databases smaller than 1GB handle file locks?)
Completely unaware of this fact, we did not insert the special page at the 1GB mark, which meant SQLite saw the file as corrupted.
Thankfully, Nikita (AKA Large Language Nikita, or LLN) apparently had the freaking source code in his training data. So he just knows that.
I work with systems that are implementing specifications. Either explicit specifications, like POSIX (in the case of the Linux Kernel), or implicit specification (in the case of Scylla, which was a rewrite of Apache Cassandra in C++).
I remember a lot of oddities and surprising behaviors that end up making it into the system and then just become part of the specification, whether intended or not. I have dealt with firmware vendors that introduced subtle synchronization bugs in timekeeping for old x86 hardware.
But a special page with a “pending” byte in the 1GB mark, that’s a first. And credit where credit is due to the amazing folks at SQLite: at least it is documented! (the SQLite source code is, as you would expect, tremendously well documented. Hipp certainly deserves his reputation)
And since it is documented, we can just get an LLN to parse it. And the fix is in.