Beyond the Single-Writer Limitation with Turso's Concurrent Writes
With multi-core processors and multi-threaded architectures becoming the norm, the old single-writer model that SQLite pioneered has started to show its age in today’s concurrent world.

Modern applications demand more from their database than ever before. With multi-core processors and multi-threaded architectures becoming the norm, the old single-writer model that SQLite pioneered has started to show its age in today’s concurrent world. Although SQLite is the most ubiquitous database there is, we believe the single-writer concurrency model limits its ability to truly be deployed everywhere.
Today we announce Turso Beta, featuring a tech preview of concurrent writes.
When concurrent writes are used, we achieve up to 4x the write throughput of SQLite, while also removing the dreaded SQLITE_BUSY error that is all too familiar to many SQLite users.
#The Single-Writer Bottleneck
SQLite has a single-writer transaction model, which means whenever a transaction writes to the database, no other write transactions can make progress until that transaction is complete. Of course, SQLite is a highly optimized piece of software and can easily write 500k rows per second with proper batching. However, there's a catch! Adding more threads doesn't scale the writes, and when your transactions need to perform business logic or other processing, you're stuck waiting. That exclusive write lock prevents any concurrency, leaving your CPU cores underutilized.
Many developers using SQLite have experienced this: when a database is locked, they encounter the dreaded SQLITE_BUSY error. You don't need a high-volume application to encounter this issue; even modest concurrent access patterns can trigger blocking scenarios that complicate your code.
The single-writer model can be a major bottleneck for write-intensive applications.
For example, let's take the following benchmark that executes 100 row inserts per transaction using SQLite:
let mut stmt = conn.prepare("INSERT INTO test_table (id, data) VALUES (?, ?)")?;
conn.execute("BEGIN", [])?;
for i in 0..100 {
let id = thread_id * iterations * batch_size + iteration * batch_size + i;
stmt.execute([&id.to_string(), &format!("data_{id}")])?;
}
conn.execute("COMMIT", [])?;
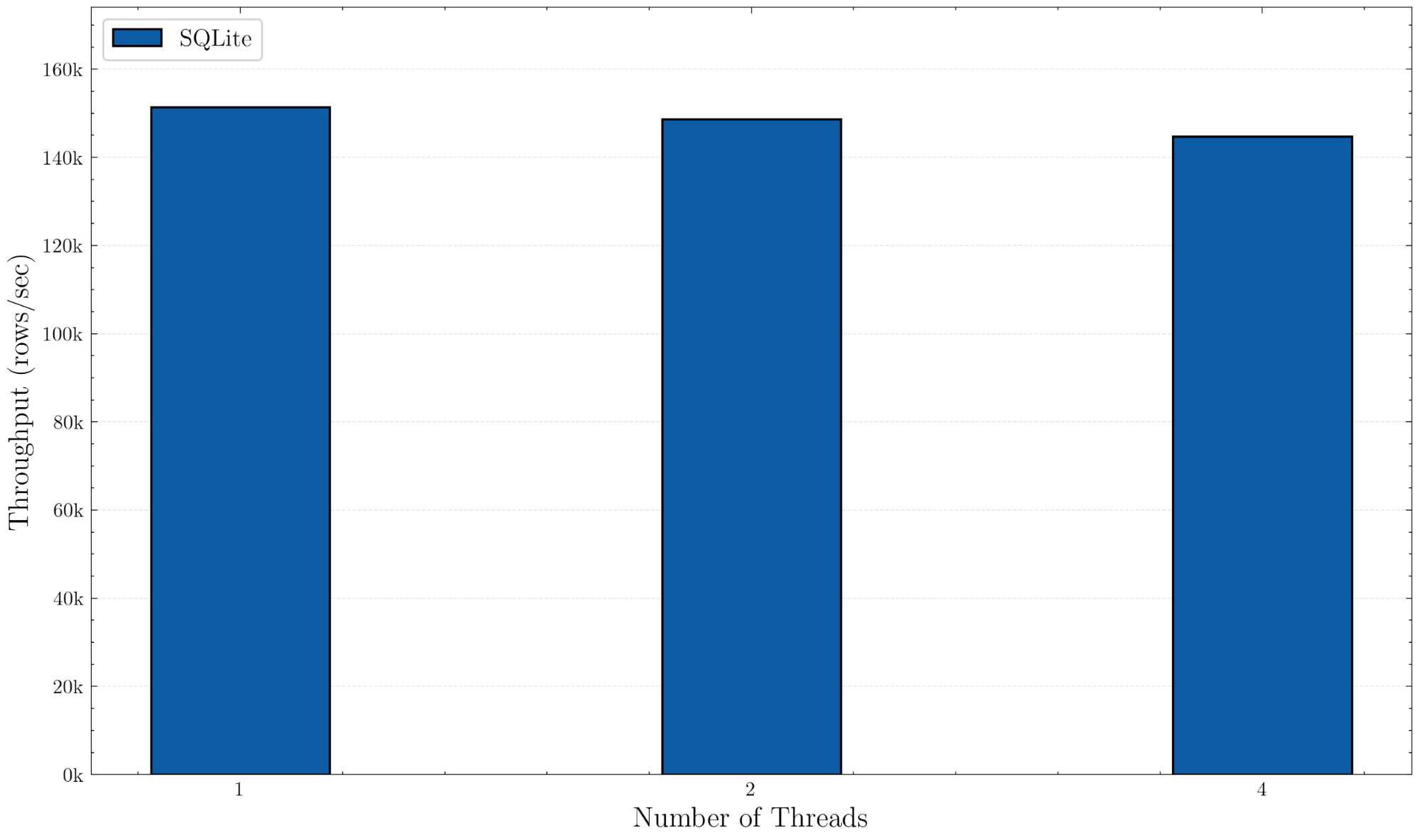
As shown in Figure 1, SQLite achieves an impressive throughput of 150k rows per second, even with full synchronous mode, which ensures that transactions are durable by calling fsync() for every commit. However, we can also see from Figure 1 that due to the single-writer model of SQLite, adding more threads does not provide any improvement to throughput.
The disadvantages of the global write lock are amplified even further when an application needs to perform other work during an interactive write transaction. For example, it might need to read from the database or perform computation such as parsing, aggregation, or ML inference.
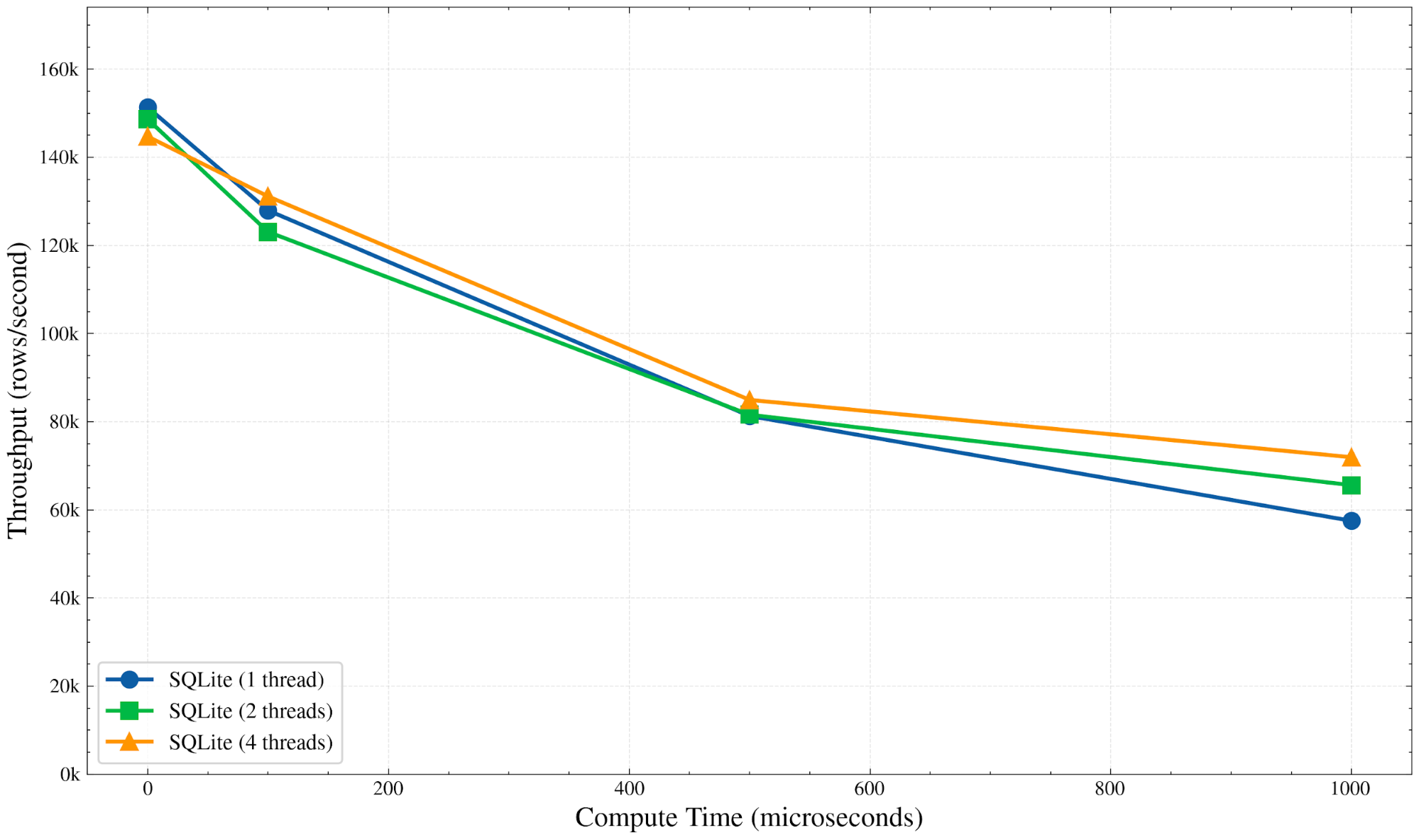
To measure the impact of computation as part of a transaction, let’s extend our benchmark to call a perform_compute() function, which is a CPU busy loop simulating some real work:
let mut stmt = conn.prepare("INSERT INTO test_table (id, data) VALUES (?, ?)")?;
conn.execute("BEGIN", [])?;
let result = perform_compute(compute_usec);
std::hint::black_box(result);
for i in 0..batch_size {
let id = thread_id * iterations * batch_size + iteration * batch_size + i;
stmt.execute([&id.to_string(), &format!("data_{id}")])?;
}
conn.execute("COMMIT", [])?;
As shown in Figure 2, SQLite throughput drops as compute time increases, regardless of how many threads you throw at it. That’s an expected result of the single-writer transaction model: only one thread can make progress at a time and as we’re performing computation as part of the transaction, we’re unable to parallelize the work.
#Hello MVCC!
SQLite has been experimenting with a feature called BEGIN CONCURRENT to mitigate the single-writer bottlenecks. This feature, available only in experimental branches and not yet merged into the official mainline SQLite release, enables multiple writers to initiate transactions concurrently when the database is in WAL mode. Unlike the traditional write transactions, where the database lock is acquired upfront, BEGIN CONCURRENT defers locking until the commit phase, enabling several write transactions to proceed in parallel optimistically.
Although this mitigates the problem somewhat, conflict detection in SQLite’s BEGIN CONCURRENT is still at the page level. This means that when two transactions update different rows that happen to be colocated on the same page, one of the transactions must still abort, even though no logical conflict has occurred.
For Turso, we’ve ended up going even further than this. We are implementing BEGIN CONCURRENT transaction mode using multi-version concurrency control (MVCC) inspired by the approach used in the Hekaton system [1, 2]. In short, MVCC enables concurrent transactions to make progress by maintaining an in-memory index that tracks row versions, a technique used in many other database systems. Whereas SQLite locks the entire database during write transactions to prevent concurrent modifications, MVCC is an optimistic concurrency control mechanism that allows transactions to write concurrently, checking for row-level conflicts only at commit time.
To understand how MVCC works, let’s look at the following example following database schema and transactions:
– The table represents product inventory.
CREATE TABLE products (name, quantity);
– Transaction T1
BEGIN CONCURRENT;
INSERT INTO products VALUES (‘Mug’, 100);
COMMIT;
– Transaction T2
BEGIN CONCURRENT;
INSERT INTO products VALUES (‘Teapot’, 500);
COMMIT;
– Transaction T3
BEGIN CONCURRENT;
UPDATE products SET quantity = quantity - 1 WHERE name = 'Mug';
COMMIT;
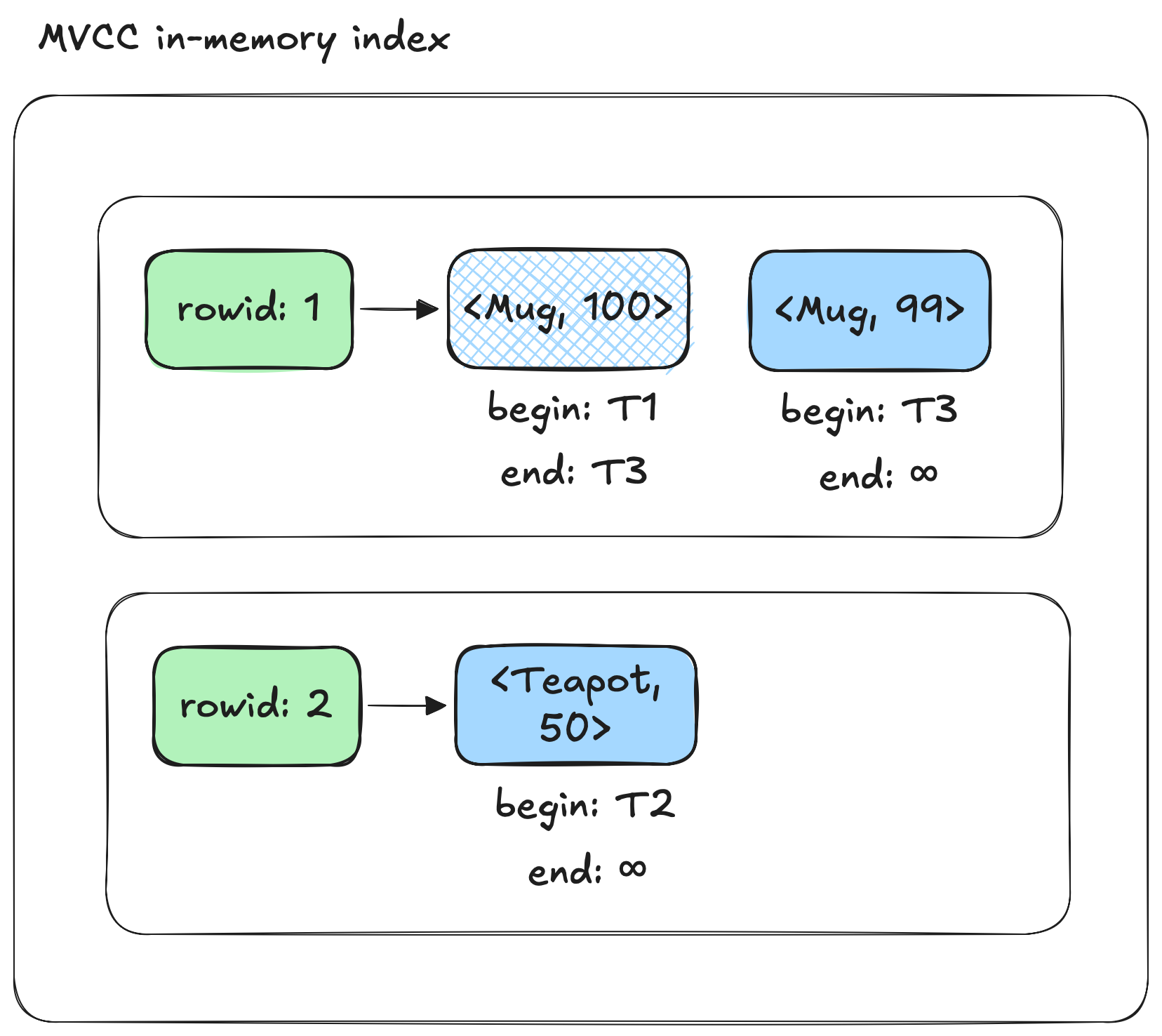
The MVCC index, illustrated in Figure 3, would contain rows:
- R1 (rowid = 1): "Mug"
- R2 (rowid = 2): "Teapot"
R1 has two versions:
- Version 1: Valid from T1 to T3
- Version 2: Valid from T3 onward
R2 has one version:
- Version 1: Valid from T2 onward
The begin and end timestamps define how the different versions are visible across the transactions:
- T1: Sees R1 (version 1) only
- T2: Sees R1 (version 1) and R2
- T3: Sees R1 (version 2) and R2
In other words, the MVCC index allows multiple transactions to make progress even if they’re concurrently updating the database because the rows are versioned.
In the case where transactions have a conflict, the MVCC algorithm detects that at commit time, and aborts the conflicting transaction returning a write-write conflict error. If the transaction has no conflicts, it is written to a log file and synced to disk.
The way we adapted Hekaton MVCC to SQLite is by layering it on top of the B-Tree and the WAL. If a row does not exist in the MVCC in-memory index, we read it through the pager from WAL and B-Tree. If a row exists in the MVCC index, we use it, because it’s the latest version due to the fact all writes go through the MVCC index. We also eventually checkpoint the MVCC log into the SQLite database file via the WAL, which simplifies recovery.
#Benchmarking Concurrent Writes
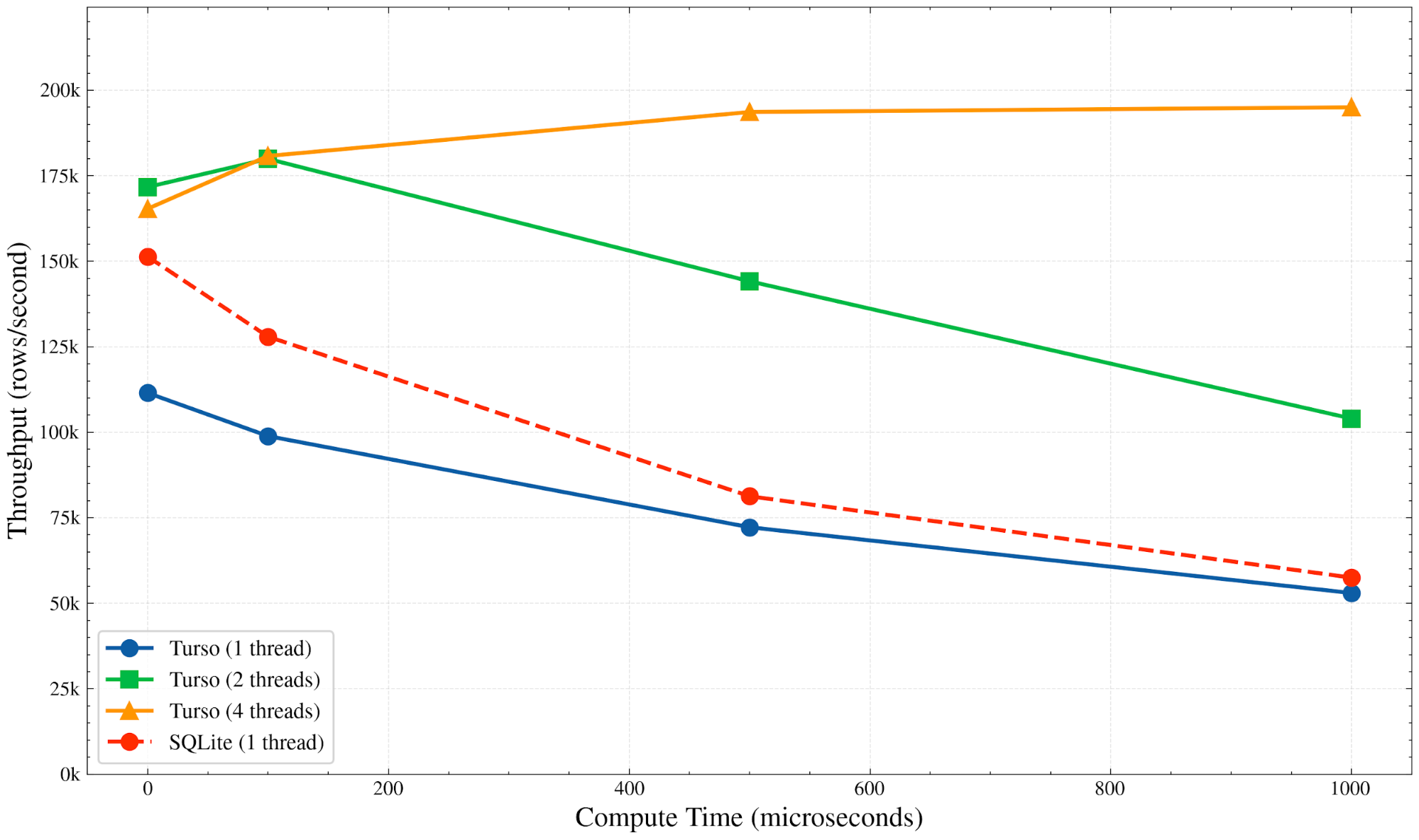
What would happen if we were to re-run our previous benchmark, but now using Turso with MVCC? When there is no compute time, and a single thread is used, SQLite actually outperforms Turso. We consider this to be a temporary state of affairs. Given how early the project is, there are lots of optimizations still to be pursued (we list some at the end of this article).
However, Turso is 16% faster than SQLite when more threads are used and there is no compute time (all the system is doing is writing rows). MVCC is able to take advantage of parallelism. And more importantly, because SQLite’s throughput drops precipitously as the transaction is interleaved with compute, the difference is even larger.
For workloads with 1ms of compute time, and 8 threads, Turso write transactions are 4x faster than SQLite’s.
It is important to note that the difference would only grow as the transaction gets more complex (larger compute time)
#Beyond the Benchmarks
The single-writer limitation isn't just a theoretical concern. Many use cases would benefit from SQLite's simplicity and embeddability, but must use client-server databases over the network due to their write concurrency needs.
Transactions with business logic. Applications often don't just perform simple inserts to the database. Instead, transactions involve a mix of reading from the database, performing business logic, and then writing to the database. For example, an e-commerce checkout might read inventory levels, check pricing rules, validate discount codes, calculate taxes, and update multiple tables in a single transaction to ensure consistency. With SQLite's single-writer model, this entire sequence holds an exclusive lock, blocking all other operations in the system and, therefore, limiting concurrency. Concurrent writes solve this problem by allowing multiple transactions to make progress simultaneously, thereby maintaining high throughput.
High-volume data ingestion. In real-time data processing, applications must ingest millions of rapidly changing data points. For example, in betting analytics systems, betting odds for events are ingested. Where each event can have thousands of odds lines that can change five times or more per second, they are also all correlated, so if a significant event occurs, all lines can move. Then, because we're analyzing hundreds of clients all offering lines, a critical change in an event can unleash a torrent of writes, and that's just for one event. When you have thousands of events active at any point in time, it's critical that you can scale your write throughput.
Materializing streams. Stream processing systems can process events at insane speeds, but you still need to materialize portions of these streams into a queryable state for many use cases. Embedding SQLite directly into the stream processor eliminates costly data movement because you can materialize events where they're processed. However, the single-writer model becomes a critical bottleneck. A stream processor might handle thousands of events per second across multiple partitions, with each event updating different materialized views. Without concurrent writes, you either serialize all updates through a single thread (limiting throughput) or maintain separate SQLite databases per partition (complicating queries). With concurrent writes at the database level, you have more flexibility in how you partition, while retaining high throughput.
Aggregations and data augmentation. Many applications continuously augment their data with computed values. For example, perform hourly aggregates, ML predictions, or classification labels. For example, an e-commerce platform might periodically calculate customer lifetime value, product recommendation scores, or fraud risk assessments. The batch computations read large amounts of data and write back augmented results. With SQLite's single-writer model, this augmentation is not practical because as soon as you start the aggregation jobs, which may take tens of seconds or minutes, you’re blocking the whole database. Concurrent writes allow these augmentation processes to run alongside normal operations, keeping data fresh without sacrificing availability.
#Limitations and Future Work
The MVCC implementation in Turso is currently in an early technology preview stage, indicating it is intended for experimental use and evaluation, rather than production use. For example, the MVCC implementation currently does not support CREATE INDEX and eagerly populates the MVCC in-memory index. The implementation also has some performance limitations on row version management and concurrency that we'll be working on.
Row version representation is inefficient. The current implementation stores complete copies of entire rows. This design choice, despite being simple, results in substantial memory overhead, particularly for tables with large rows or high update frequencies. For example, a single column in a 1KB row is updated multiple times. In that case, each version consumes the full 1KB rather than just storing the modified fields, quickly leading to memory exhaustion in write-heavy scenarios. To make the MVCC index more memory-efficient, we should explore using row deltas instead of full rows when we can.
Row version management is not wait-free. The row versions are managed by a contiguous vector that is protected by a read-write lock. The lack of a wait-free data structure creates a bottleneck that limits scaling concurrent write operations on multicore. In a wait-free system, operations complete in a bounded number of steps regardless of other concurrent operations, enabling predictable performance under load. Without this guarantee, writers may experience unpredictable delays as they contend for access to shared resources, leading to degraded performance as concurrency increases.
Concurrent transactions don't use asynchronous I/O. The concurrent transaction handling in the current implementation doesn't utilize asynchronous I/O, which limits scalability. Without this optimization, transactions block on I/O operations, wasting valuable CPU cycles and, therefore, limiting the number of concurrent transactions the system can effectively handle. For example, in mixed read-write workloads or computationally intensive transactions, asynchronous I/O will better leverage storage-level parallelism and reduce CPU usage. The way we’ll solve this problem is by working towards enabling io_uring by default.
#Usage
To use mvcc, pass the --experimental-mvcc flag.
$ tursodb --experimental-mvcc database.db
> BEGIN CONCURRENT;
> CREATE TABLE t(v);
> INSERT INTO t(v) VALUES (42);
#Summary
Concurrent writes with multi-version concurrency control (MVCC) achieve up to a 4x improvement in write throughput in our early testing. By allowing multiple transactions to proceed simultaneously rather than blocking behind a single writer, concurrent writes eliminate the SQLITE_BUSY errors that plague production SQLite applications, enabling use cases such as high-volume data ingestion, stream materialization, and continuous data augmentation that were previously impractical. While this technology preview has limitations, it represents a step forward: bringing true write concurrency to SQLite without sacrificing the simplicity that makes it the world's most deployed database.

[1]: Per-Ake Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. "High-performance concurrency control mechanisms for main-memory databases." In VLDB '12.
[2]: Justin J. Levandoski, David B. Lomet, and Sudipta Sengupta. 2013. "The Bw-Tree: A B-tree for new hardware platforms". In ICDE '13.