
When working with large schemas in SQLite, even simple schema changes can become surprisingly slow. A single ALTER TABLE operation can drag on when dealing with databases containing hundreds of tables. This performance bottleneck stems from a fundamental aspect of how SQLite manages its schema information.
In this article, we will see how Turso, an Open Contribution project aiming at rewriting SQLite in Rust, fixes this issue.
#The SQLite Schema Performance Problem
SQLite stores schema information in a special table called sqlite_schema. This table must be scanned and kept in memory to resolve identifiers during statement preparation. While this design works well for smaller databases, it creates a significant performance penalty as schemas grow.
When you perform schema modifications through ALTER TABLE, SQLite follows a three-step process:
- Write the changes to the
sqlite_schematable - Increment the schema cookie (used to signal a schema change to prepared statements)
- Scan the schema table and update the in-memory schema.
Because the sqlite_schema table has to be re-parsed, the time it takes to update the in-memory schema is proportional to the size of the entire schema, even for operations that only modify a few entries. When you DROP COLUMN from a single table, SQLite will scan all schema entries for changes, not just the affected table and its indexes.
#Turso's Solution: Direct Schema Mutations
Instead of reparsing the whole schema, we can use information about the current modification to make targeted changes to the in-memory schema, avoiding unnecessary reads altogether. Trading generality, by optimizing the common cases.
Each ALTER TABLE operation now has its own specialized bytecode instruction that directly modifies the schema in memory.
The results are as follows:
- Direct schema mutation – add
RenameTableinstruction
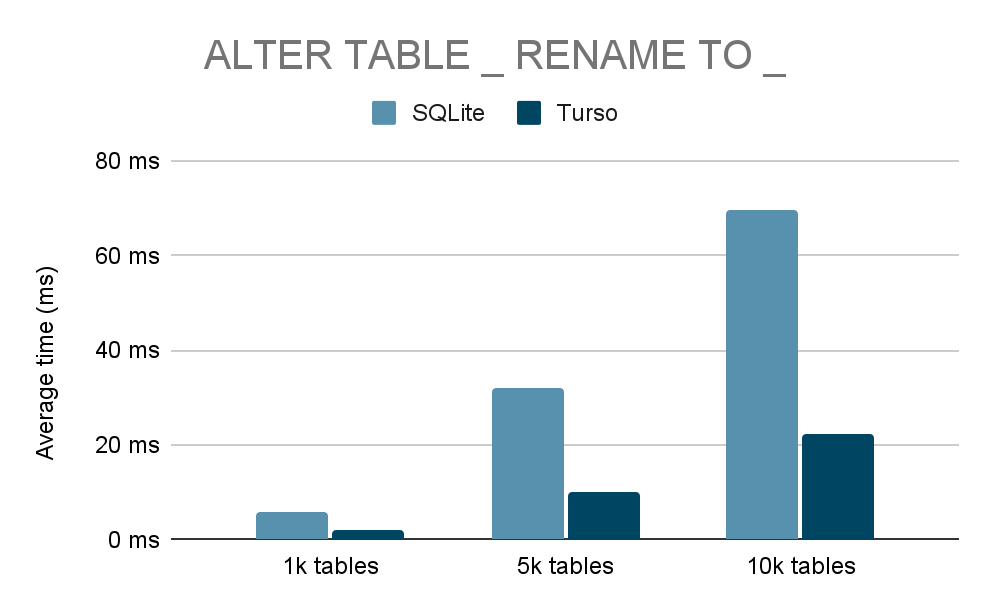
- Direct schema mutation – add
DropColumninstruction
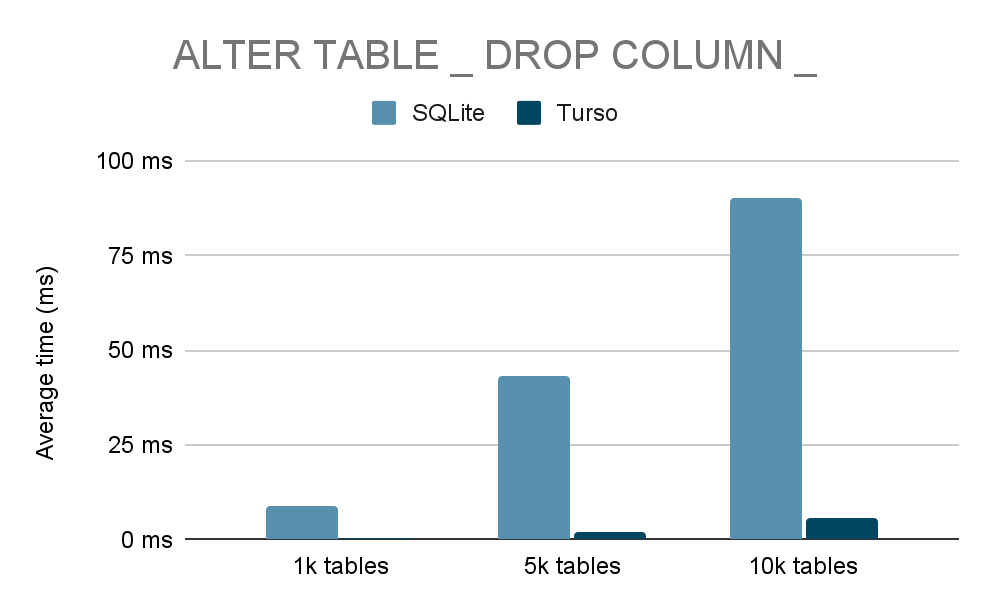
- Direct schema mutation – add
AddColumninstruction
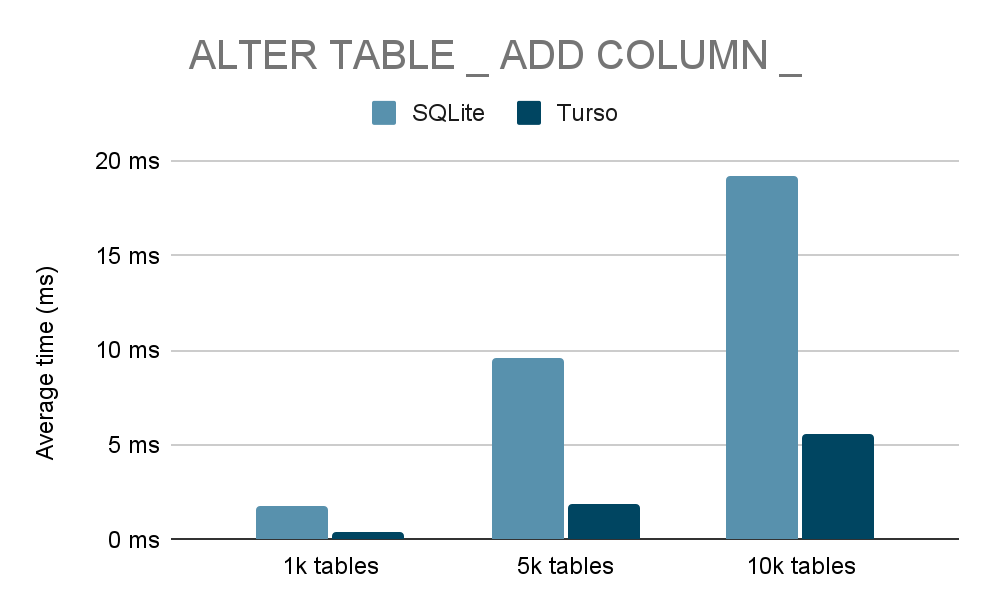
- Direct schema mutation – add
RenameColumninstruction
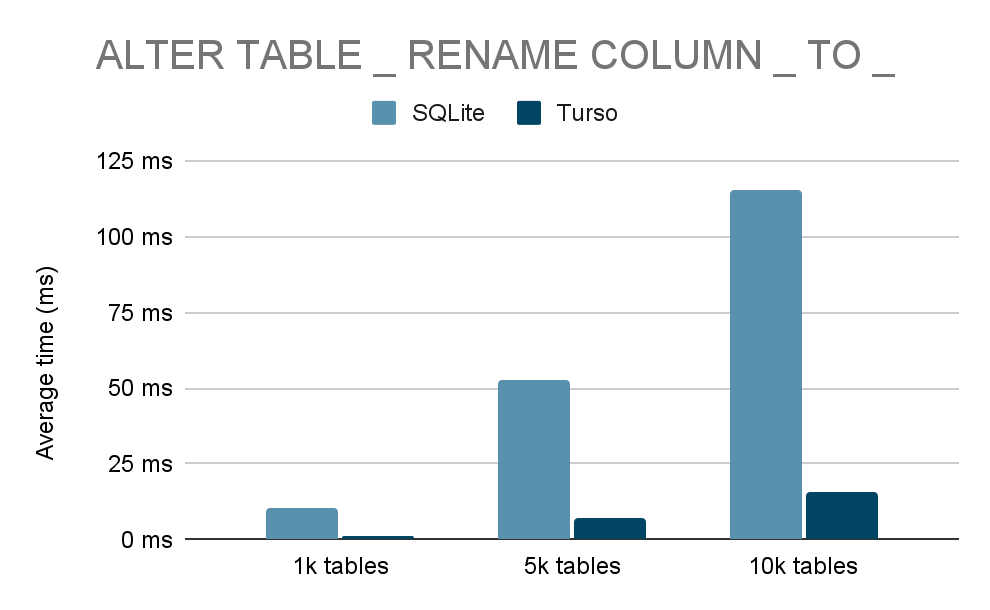
Operations like column and table renaming require special consideration since they also affect indexes. We optimized these by only mutating the set of indices related to that specific table in batch, rather than scanning the entire schema.
#Optimizing Initial Schema Parsing
Direct mutations solve the problem for ongoing schema changes, but there's another major bottleneck: the initial connection setup. When a new connection is established, the in-memory schema must be populated from scratch, requiring a scan and parse of all schema entries. For large schemas, this initial cost can be substantial.
As we detailed in our previous post about making SQLite connections 575x faster, opening a connection to a database with 10,000 tables took 23ms in standard SQLite. Through schema sharing between connections and other optimizations, we reduced this to just 40 microseconds regardless of schema size.
But even with shared schemas, the first connection still needed to parse the entire schema from the sqlite_schema table. The primary overhead here comes from raw SQL parsing speed. Originally, we used SQLite's lemon parser generator with the grammar adapted for Rust. While this approach ensured compatibility, it limited our control over performance optimizations.
By implementing a handwritten parser (#2381), we gained the flexibility needed for targeted performance improvements:
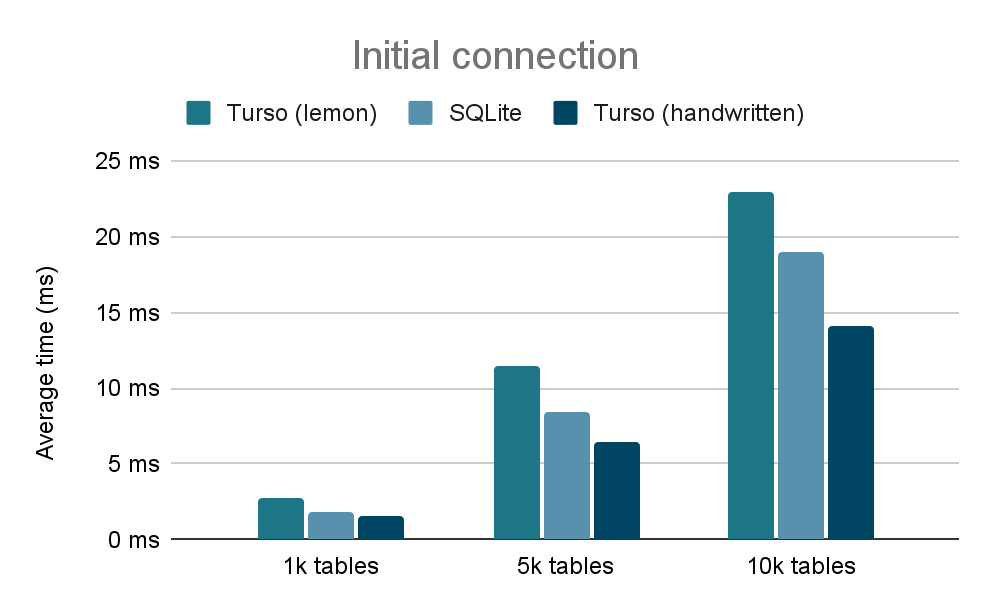
This parsing optimization works hand-in-hand with our connection sharing: the first connection parses the schema faster, and subsequent connections skip parsing entirely by sharing the in-memory representation.
#Try it out!
If you're dealing with large schemas and slow ALTER TABLE operations, you can experience these performance improvements firsthand by downloading the Turso shell with curl -sSL tur.so/install | sh, or with your favorite SDK.
Turso is rewriting SQLite to comply with the demands of the modern world. But the most important part for us is its Open Contribution nature. While SQLite is a closed community without external contributors. Turso already has over 130 contributors.
Want to be a part of what the future of embedded databases looks like ? Check us out on Github! You can star the Turso repository, and look at some of the issues marked as “Good First Issue”