
At Kin, we combine vector search with metadata queries to create sophisticated RAG (retrieval-augmented generation) pipelines in our AI agents.
In today’s AI-driven world, managing vast amounts of data while keeping it relevant and accessible is a significant challenge, especially when working with large language models (LLMs) and vector databases. Integrating vector search with metadata has become an effective approach, especially in RAG pipelines, as it enables faster and more accurate data retrieval. However, applying pre- and post-search filtering is crucial to ensure data relevance.
#The Challenge of Vector Search with Metadata
In a typical vector search, embeddings are created from text chunks, like those in a PDF document, to enable the retrieval of similar items based on relevance. The challenge arises when vector search results need to be combined with structured metadata. For example, timestamped text-based content might require retrieving the most relevant data within a specific date range. Here, metadata is essential for refining search results.
Unfortunately, most vector databases treat metadata as secondary, separate from the primary vector search process. Consequently, handling queries that combine vectors and metadata can be challenging, especially when incorporating dynamic filters, such as date ranges or other structured data.
#libSQL and Vector Search with Metadata
libSQL, a more general-purpose SQLite-based database, adds vector capabilities to traditional data, with vectors stored as blob columns in standard tables. This setup makes vector embeddings and metadata first-class citizens, enabling deep integration of these data points.
CREATE TABLE IF NOT EXISTS conversation (
id VARCHAR(36) PRIMARY KEY NOT NULL,
startDate REAL,
endDate REAL,
summary TEXT,
vectorSummary F32_BLOB(512)
);
With libSQL, metadata and vector search challenges are resolved, bridging the gap between vector data and regular structured data in the same storage, as seen in the example query below:
const sqlQuery = `
SELECT c.id, c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) AS distance
FROM conversation c
WHERE
${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''}
${distance ? `AND distance <= ${distance}` : ''}
ORDER BY distance
LIMIT ${top};
`;
The vector_distance_cos function calculates distance, allowing basic vector searches to perform a full scan and calculate distances. This approach can be optimized with common table expressions (CTEs) to limit search and distance calculations to a smaller data subset.
For more efficient searches, libSQL offers FlashDiskANN vector indexing:
const sqlQuery = `
vector_top_k('idx_conversation_vectorSummary', ${vector}, ${top}) AS i
`;
#Post-Filtering: A Common Approach
The most common approach in these pipelines is post-filtering, where data is retrieved based on vector similarity and then filtered by metadata. For instance, you might search for conversations relevant to a specific question and also want to ensure they occurred in the past week.
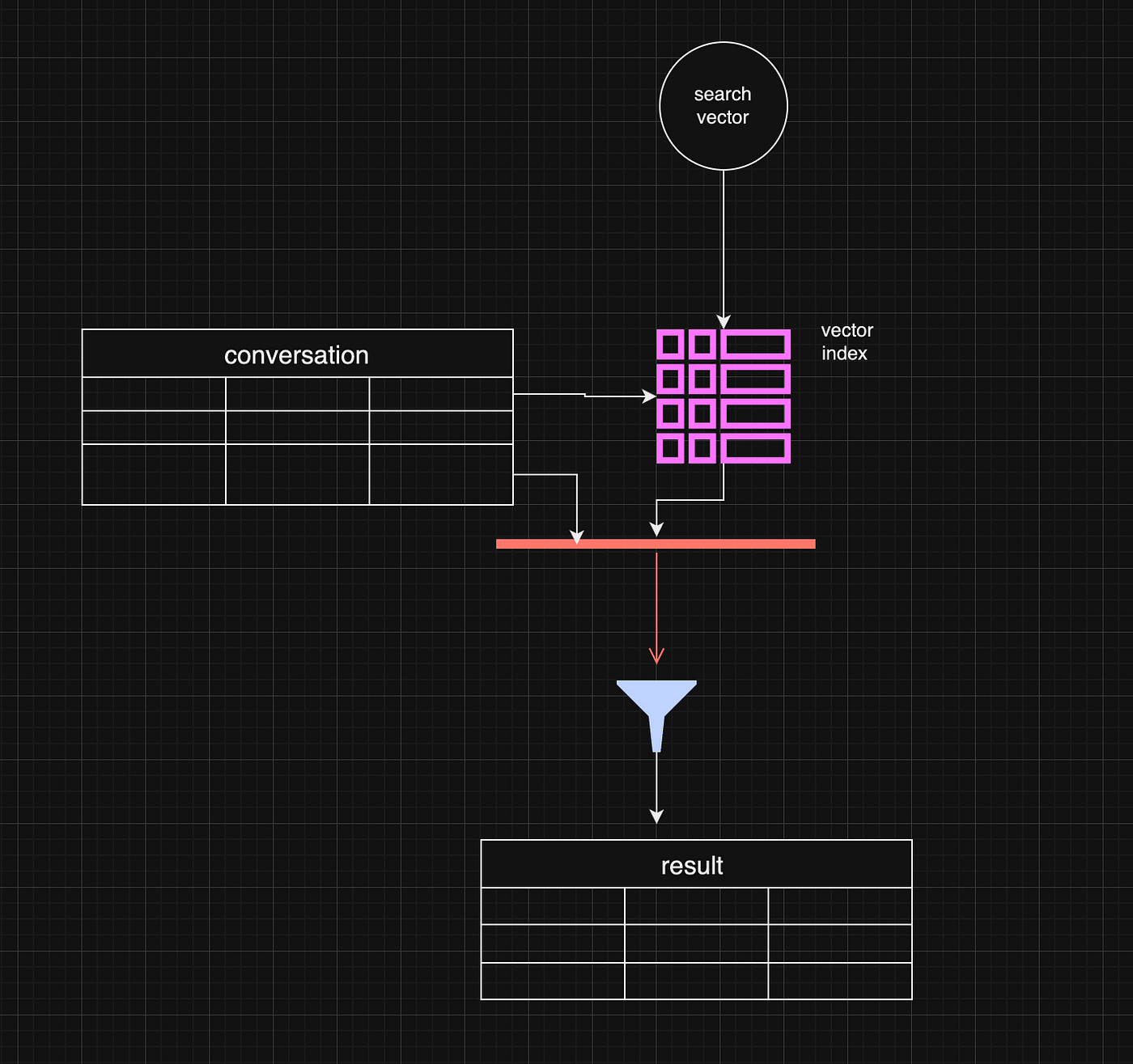
Post-filtering retrieves the most relevant vector-based results, then excludes any that don’t meet the metadata criteria, such as a specific date range. This is efficient when vector similarity drives the search, with metadata as a secondary filter.
const sqlQuery = `
SELECT c.id, c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) AS distance
FROM vector_top_k('idx_conversation_vectorSummary', ${vector}, ${top}) AS i
INNER JOIN conversation c ON i.id = c.rowid
WHERE
${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''}
${distance ? `AND distance <= ${distance}` : ''}
ORDER BY distance
LIMIT ${top};
`;
One limitation is that the initial vector search might return too few results or omit relevant data before the metadata filter is applied. A common strategy is to set a larger top value in vector_top_k, but note that the default max result count is around 200 rows.
#Pre-Filtering: A More Complex Approach
Pre-filtering uses metadata as the primary filter before vector search, passing only data that meets metadata criteria into the vector search process. This approach can reduce irrelevant data in the final results but may require denormalizing data or creating separate pre-filtered tables, which can be resource-intensive.
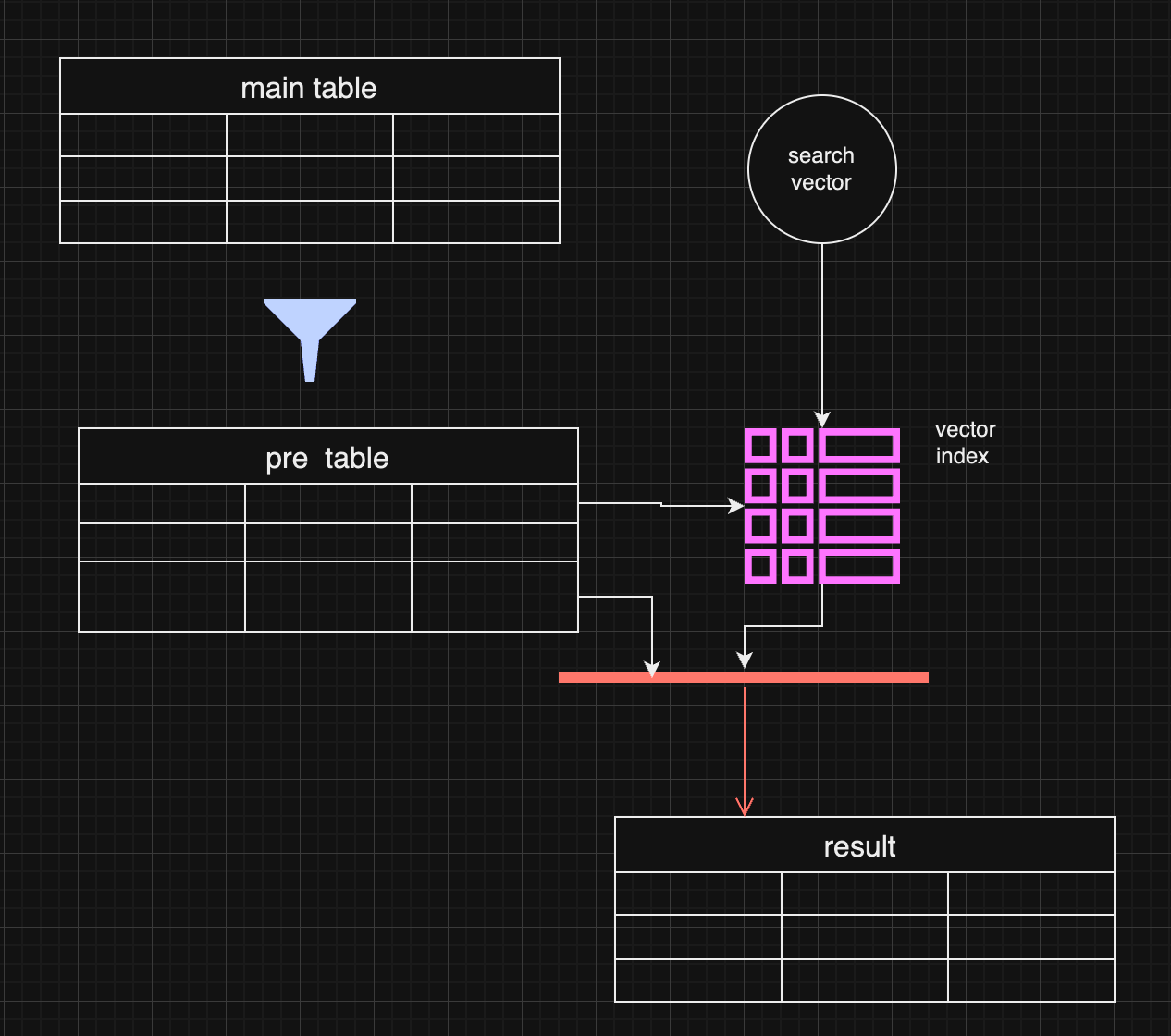
In cases where metadata, such as date ranges, is the most critical filter, pre-filtering ensures searches are conducted only on relevant data.
#Pre-Filtering with Distance-Based Filtering
Returning to a traditional concept, pre-filtering without vector indexing can still be effective:
const sqlQuery = `
WITH FilteredDates AS (
SELECT
c.id,
c.startDate,
c.endDate,
c.summary,
c.vectorSummary
FROM
YourTable c
WHERE
${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''}
),
DistanceCalculation AS (
SELECT
fd.id,
fd.startDate,
fd.endDate,
fd.summary,
fd.vectorSummary,
vector_distance_cos(fd.vectorSummary, vector(${vector})) AS distance
FROM
FilteredDates fd
)
SELECT
dc.id,
dc.startDate,
dc.endDate,
dc.summary,
dc.distance
FROM
DistanceCalculation dc
WHERE
1=1
${distance ? `AND dc.distance <= ${distance}` : ''}
ORDER BY
dc.distance
LIMIT ${top};
`;
This approach is effective if the initial filter results in a small dataset, as distance calculations are then performed on a limited dataset.
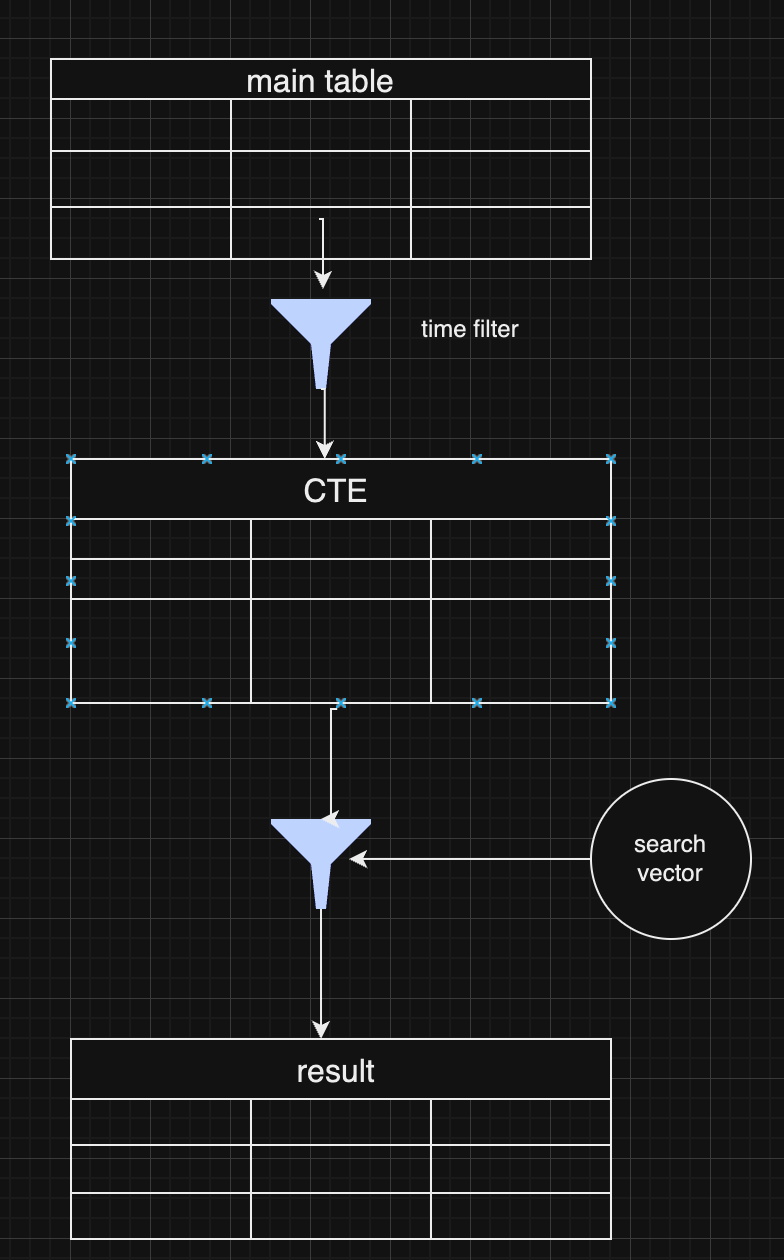
This method allows for full data control without omitting typical values in extensive index searches.
#Choosing Between Pre- and Post-Filtering
Both pre- and post-filtering have unique advantages. Post-filtering is simpler to implement when vector similarity is the primary criterion but can lead to incomplete results. Pre-filtering offers more precise results but requires complex data handling and optimization.
Many systems combine both strategies depending on the query—beginning with a broad pre-filter based on metadata (like date ranges), followed by post-filtering to refine the results further.
#Conclusion
Vector search with metadata filtering is a powerful tool for handling large-scale data retrieval in LLMs and RAG pipelines. Whether you choose pre-filtering, post-filtering, or a hybrid approach depends on your specific requirements. As vector databases evolve, we anticipate innovations that will combine these methods more seamlessly, enhancing data relevance and retrieval efficiency.
#Interested?
If this sounds interesting and you’d like to work with us on these exciting projects, please reach out.