
Developers are building the next generation of intelligent productivity apps, personal assistants, and more by taking advantage of Large Language Models.
These models are deep learning algorithms that can perform natural language processing tasks such as text generation, summarization, and translation. Despite their ability to train on vast datasets, these models are confined to the information they've absorbed during training. This can lead to outdated or stale knowledge or even hallucination, where the LLM generates a creative response on a topic it does not know about.
Building applications with Large Language Models requires the models to produce accurate and relevant output. While it's possible to fine-tune the models to train them incrementally to keep them updated, the approach can be impractical when your application needs to access private or specific data because you would, for example, need to fine-tune a model per user. That's why many applications are adopting the Retrieval-Augmented Generation (RAG) approach, which allows applications to augment the model with up-to-date and specific information using, for example, a vector database, which provides a reliable and efficient way to overcome the limitations of LLMs.
#Retrieval-Augmented Generation (RAG)
To highlight the need for RAG, let’s first look at how we use just the model itself. As illustrated in the following diagram, to work with a LLM, you pass a prompt as an input to the model, which generates an output.

Let’s say we have a model that was trained some time in the year 2022. We could give it a prompt such as:
What is the latest movie featuring the character Indiana Jones?
And the model would output something like:
The latest movie where the character Indiana Jones appears is the Indiana Jones and the Kingdom of the Crystal Skull, released in 2008.
Although the answer looks convincing, it’s in fact wrong because there is a newer movie released in 2023 featuring the character. But as the model did not see this information in training, it has no knowledge about it.
We can solve this by using Retrieval-Augmented Generation, splitting the process into two parts — retrieval and generation.
In the retrieval part, we use the prompt to retrieve relevant information from an external knowledge source. We then take the retrieved information and rewrite the prompt to include that information.
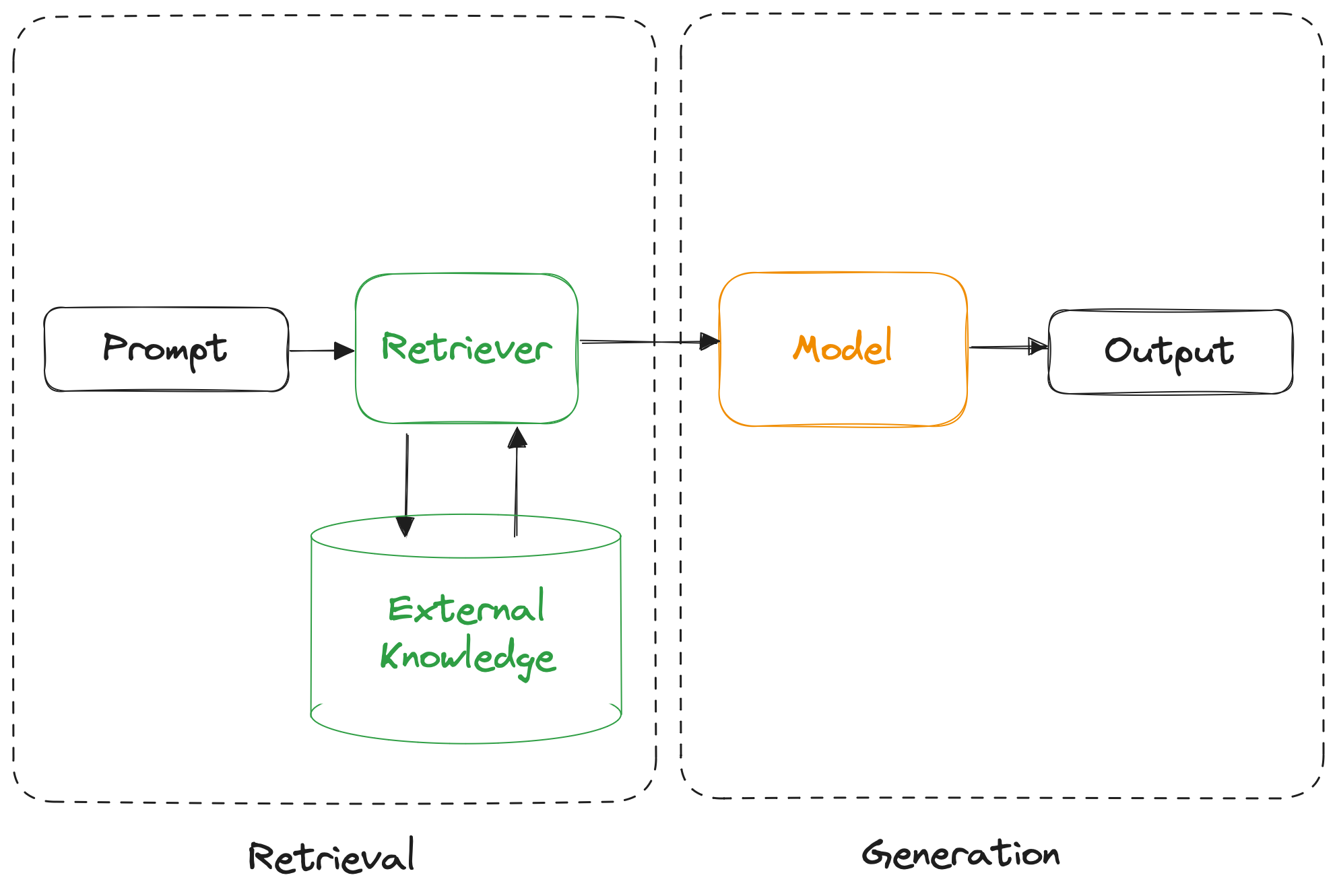
For example, the retriever could search for movies featuring the Indiana Jones character and include them in the new prompt as follows:
Given the following list of Indiana Jones movies (release year in parenthesis):
- Raiders of the Lost Ark (1981)
- Indiana Jones and the Temple of Doom (1984)
- Indiana Jones and the Last Crusade (1989))
- Indiana Jones and the Kingdom of the Crystal Skull (2008)
- Indiana Jones and the Dial of Destiny (2023)
Please answer the following question:
What is the latest movie featuring the character Indiana Jones?
The model would then output something like:
The latest movie featuring the character Indiana Jones is Indiana Jones and the Dial of Destiny, released in 2023.
Awesome! But how exactly does retrieval find relevant information? A popular option today is to use embeddings and vector search.
#Embeddings and Vector Search
Embeddings are an abstract representation of a thing and the key component in finding relevant information with vector search. Large Language Models can generate output based on text, but they can also generate embeddings, which are vector representations of a text that attempts to capture the semantics of the text.
For example, the plot synopsis for Indiana Jones and the Temple of Doom movie on Wikipedia looks something like:
In 1935, American archeologist Indiana Jones survives a murder attempt from Shanghai crime boss Lao Che, who hired him to retrieve the remains of Nurhaci. Indy flees from the city in the company of the young orphan Short Round and nightclub singer Willie Scott, unaware that the plane he is traveling on is owned by Che. The plane's pilots dump the fuel and parachute away, but Indy, Willie and Short Round escape using an inflatable raft before the plane crashes.
We can use a large language model to generate an embedding that might look something like this:
[-0.28081661462783813,-0.19738759100437164,0.02586386539041996,0.024890132248401642,0.07714278995990753,-0.1713564246892929,-0.10289978235960007,0.22950506210327148,-0.0280305165797472,0.08096414804458618,0.06055774167180061,0.014634222723543644,-0.16451555490493774,-0.26197656989097595,0.23742054402828217,-0.4975569546222687,-0.00656033493578434,-0.14621023833751678,-0.2378271520137787,0.027298960834741592,0.0393340028822422,-0.1777578592300415,0.21231436729431152,-0.1742742657661438,0.34695351123809814,-0.2076600342988968,-0.380169540643692,0.14696519076824188,0.1946181058883667,0.25933799147605896,-0.017670592293143272,0.06639852374792099,-0.214995875954628,0.22445939481258392,-0.105390764772892,-0.057460349053144455,0.1052788496017456,-0.13363845646381378,-0.004564173519611359,-0.3614486753940582,-0.23518246412277222,-0.12644892930984497,0.37349656224250793,0.15370984375476837,-0.1988227367401123,0.05929525941610336, …]
The length of embedding vectors depends on the model, but typically they’re between 512 to 1024 bytes.
We can also generate an embedding for a prompt such as the one in our example:
What is the latest movie featuring the character Indiana Jones?
To retrieve relevant information for our prompt, we can use vector search to find embeddings of movie plots that are similar to the prompt to discover the movie titles and their release year, and add that information in a rewritten prompt that we give to the LLM to generate the final output.
To perform the similarity search efficiently, there are special-purpose vector databases such as Pinecone, but there are also database extensions such as pgvector for Postgres, and libSQL's native vector search.
#Vector Search in SQLite
In a relational database, embeddings can be just columns as part of the data.
We might have a table called movies with movie title, release year, and embedding as columns:
CREATE TABLE movies (
title TEXT,
year INT,
embedding F32_BLOB(3)
);
If you have used SQLite before, the F32_BLOB(3) column type probably looks a bit odd — However, SQLite column types are treated more as hints than anything, so this part requires no changes to SQLite, the embedding column will essentially be a blob.
With a movies table, to insert vector data into the table, we implemented a vector() function, which takes a text representation of a vector and converts it into a binary representation for storing in the database. For example, adding all the Indiana Jones movies would look something like this:
INSERT INTO movies VALUES ('Raiders of the Lost Ark', 1981, vector('[3,4,5]'));
INSERT INTO movies VALUES ('Indiana Jones and the Temple of Doom', 1984, vector('[2,4,6]'));
INSERT INTO movies VALUES ('Indiana Jones and the Last Crusade', 1989, vector('[3,4,5]'));
INSERT INTO movies VALUES ('Indiana Jones and the Kingdom of the Crystal Skull', 2008, vector('[3,4,5]'));
INSERT INTO movies VALUES ('Indiana Jones and the Dial of Destiny', 2023, vector('[3,4,5]'));
As a final piece of the puzzle, we also implemented a vector_distance_cos() function, which returns the cosine distance between two vectors. We can use the function with ORDER BY and LIMIT to return the exact top-k similar vectors as follows:
SELECT title, year FROM movies ORDER BY vector_distance_cos(embedding, vector('[5,6,7]')) LIMIT 3
The SQL query performs an exact nearest neighbor search, which returns vectors closest to each other. Although this approach works well with smaller data sets, it only scales to small amounts of embeddings. Every query has to traverse through all of them because the SQL query is a full table scan.
What we need to scale to a significant number of embeddings is an approximate nearest-neighbour search — we'll learn about that in the next installment.