How to Generate & Store OpenAI Vector Embeddings with Turso
Learn how to generate and store OpenAI Embeddings.

Previously we learned about using SQLite as your LLM Vector Database and what embeddings model are and do. Choosing an embedding model is an important decision, as it will ultimately affect the quality of your search results.
Another important factor of choosing an embedding model is cost. Some models are open source, and free to use, while others require a subscription or payment per request.
In this article, we'll be using the new and improved text-embedding-ada-002 model provided by OpenAI, which is optimized for creating text embeddings.
#Upgrade your group to use vectors
First, you will need to create a database in a Turso group that is using the vector version. This is because vector support is still in beta.
We'll be using the Turso CLI throughout this tutorial to create, connect, and query the database — install it if you haven't already.
turso group create <group-name>
Make sure to replace <group-name> with the name of your group. Typically default is used for the group name.
#Create a new database
Begin by creating a new database:
turso db create mydb
Next fetch your database URL and auth token, we'll need them later:
turso db show mydb --url
turso db tokens create mydb
Now let's connect to the database shell to create a table to store the embeddings:
CREATE TABLE IF NOT EXISTS documents (
embedding F32_BLOB(1536)
);
Notice that column embedding uses a special type F32_BLOB(1536) that is optimized for storing embeddings. The number 1536 is the number of dimensions in the OpenAI embeddings model we are using.
Next let's CREATE INDEX with diskann type and cosine metric. This is a special index type that is optimized for cosine similarity operations:
CREATE INDEX IF NOT EXISTS documents_idx
ON documents (
libsql_vector_idx(
embedding,
'type=diskann',
'metric=cosine'
)
);
To confirm everything is set up correctly, you can run the following command to see the table schema:
.schema
You should see the following output:
CREATE TABLE libsql_vector_meta_shadow ( name TEXT, metadata BLOB );
CREATE TABLE documents (embedding F32_BLOB(1536));
CREATE INDEX documents_idx ON documents ( libsql_vector_idx(embedding, 'type=diskann', 'metric=cosine') );
CREATE TABLE documents_idx_shadow (index_key INT, data BLOB);
You'll notice there are a few additional tables — those are managed internally by libSQL for your vector indexes.
#Install libSQL client
Begin by installing the @libsql/client package, if you're using something other than JS/TypeScript, you will need to use that client instead:
npm install @libsql/client
Next, create a client instance using the URL and auth token you fetched earlier:
import { createClient } from '@libsql/client';
const db = createClient({
url: '...',
authToken: '...',
});
#OpenAI API Setup
If you haven't already, sign up and create an API key with OpenAI:
Next, install the OpenAI package for your language of choice, here we are using Node.js:
npm install openai
Now import and instantiate the OpenAI client with your API key:
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: '...',
});
#Creating Embeddings
We'll be using the text-embedding-ada-002 model which is optimized for creating text embeddings:
async function createEmbeddings(
input: string | Array<string> | Array<number> | Array<Array<number>>,
) {
const response = await openai.embeddings.create({
model: 'text-embedding-ada-002',
input,
});
return response.data.map((item) => item.embedding);
}
This function takes some input and returns an array of embeddings, each embedding is an array of numbers. The model we're using produces embeddings with 1536 dimensions, which is what we set our database F32_BLOB column to.
Now let's create some embeddings for some sample text:
async function main() {
const embedding = await createEmbeddings(
'The quick brown fox jumps over the lazy dog',
);
console.log(embedding);
}
main();
If you execute this code, you should see the embeddings:
[ -0.003653927, 0.008363503, -0.01428896, -0.0045085, -0.015432579, 0.018687496, -0.020446911,
-0.010091499, -0.01285001, -0.028150633, 0.019554636, 0.017129159, 0.02172877, 0.0014962879, ....
#Storing Embeddings
Now let's write some code to process our embeddings in batches of 50 documents at a time. For each document, we create an SQL INSERT statement that adds the original content and embedding into the documents table:
const batchSize = 50;
async function storeEmbeddings(embeddings: number[][]) {
for (let i = 0; i < embeddings.length; i += batchSize) {
const batch = embeddings.slice(i, i + batchSize).map((embedding) => ({
sql: `INSERT INTO documents (embedding) VALUES (?)`,
args: [new Float32Array(embedding).buffer as ArrayBuffer],
}));
try {
await db.batch(batch);
console.log(`Stored embeddings ${i + 1} to ${i + batch.length}`);
} catch (error) {
console.error(
`Error storing batch ${i + 1} to ${i + batch.length}:`,
error,
);
}
}
}
We use the db.batch method to execute multiple SQL statements in a single transaction. This is more efficient than executing each statement individually.
#Trying it out
We're now ready to put the pieces together to generate and store embeddings with libSQL:
async function main() {
const embeddings = await createEmbeddings(
'The quick brown fox jumps over the lazy dog',
);
await storeEmbeddings(embeddings);
}
main();
If you now query your database using turso db shell, you will see the embeddings stored as a BLOB in the embedding column:
SELECT * FROM documents;
This isn't very useful currently, but we can use the documents_idx index (based on the DiskANN algorithm) we created earlier to perform similarity searches on the embeddings.
It's also useful to store the original content, and any other metadata you might have, alongside the embeddings so you can see what they represent — we'll learn about that in another post.
#Optimizing for real world
So far we've only created embeddings for the text The quick brown fox jumps over the lazy dog but when working with larger documents (such as a PDF), you'll need to split them into smaller chunks to avoid hitting the OpenAI API limits.
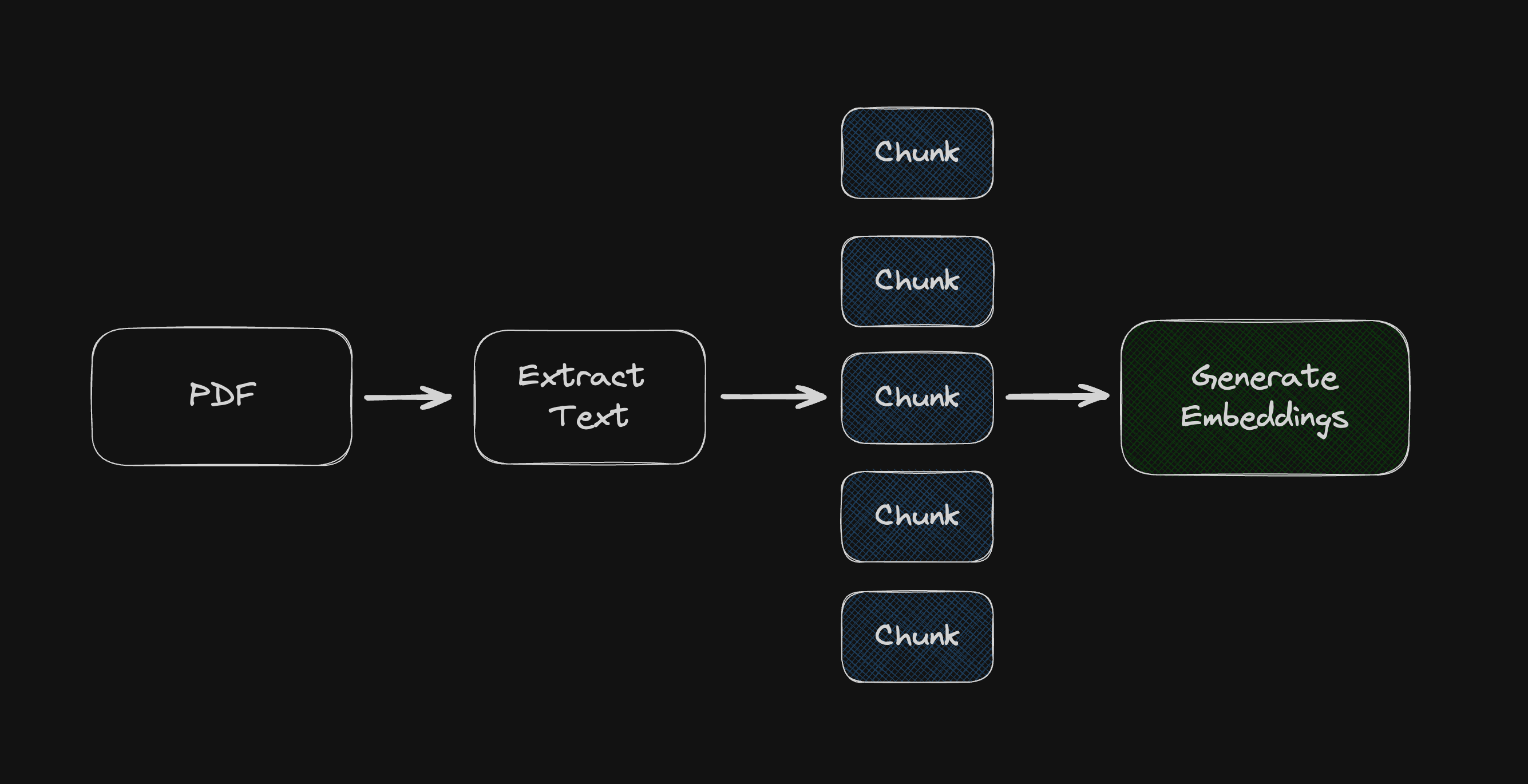
Then with the chunks we can invoke createEmbeddings() for each of them, and store them in the database as separate rows.
We'll learn more in the next post about how to handle larger documents by splitting a PDF into chunks using the pdf-parse package together with langchain's text splitter utility, Open AI, and storing each "chunk" in the database as a separate row.
If you're not already using Turso Cloud, you can sign up for free, and if you have any questions about SQLite, Vector Embeddings, or anything else — join us on Discord.