Using SQLite as your LLM Vector Database
LLMs understand, process, and generate human-like language, enabling tasks like translation, summarization, and question answering through advanced contextual learning and pattern recognition.

Vector Databases are specialized databases purpose built for use with Large Language Models (LLMs). In particular, they are used to support Vector Similarity Search by handling vector data (numeric data) that represent specific items such as text, images, audio and video. The deep learning models used to generate vectors can also understand semantic relationships between items, enabling, and making easier more advanced search capabilities.
There are other reasons to use a dedicated Vector Database, such as managing unstructured data or tighter integration with LLM models, but giving long term memory to ML models and LLMs by transforming raw data into numerical representations known as vector embeddings, bringing with it deep understanding of the relationships between data. Vector Similarity Search is the main use case you’ll come across when seeking more details about Vector Databases.
Many efforts (like pgvector for Postgres and various vector support solutions for MySQL) are ongoing to incorporate vector embeddings into popular other database offerings, making them possible replacement vector databases that more tightly integrate into your existing workflows and offer integration benefits.
And now Turso has introduced native vector embedding support for SQLite via their Open Contribution fork libSQL.
But more on this later.
#What are Embedding Models?
Embedding models vary and are tailored to process different types of input based on the data they have been trained on. Most of the data online is unstructured, and storing information about documents, images, videos, audio, and other items required manual processing to "tag" and categorize them. The process of tagging items is time consuming and prone to human error.
Embedding models have revolutionized the way we handle unstructured data. We can automate this "tagging" process, thereby saving time and increasing accuracy of similarity searches.
If you're struggling to imagine what vector databases enable in real world applications, you’re probably already consuming something today powered by a Vector Database, and Embeddings.
- Recommendations — Products, music, movies, etc.
- Similarity Search — Find similar images or documents based on user input.
- Chatbots — Use natural language processing models trained on knowledge base to answer custom questions, or process user requests via Siri, Alexa, etc.
- Fraud Detection — Detect unusual behavior using purchasing data and history.
- Content moderation — Detect harmful content by processing user uploaded media.
- And so much more…
#How Embeddings Work
The process of creating an embedding is straightforward. You take an input, process it using an embedding model, and receive an output vector.
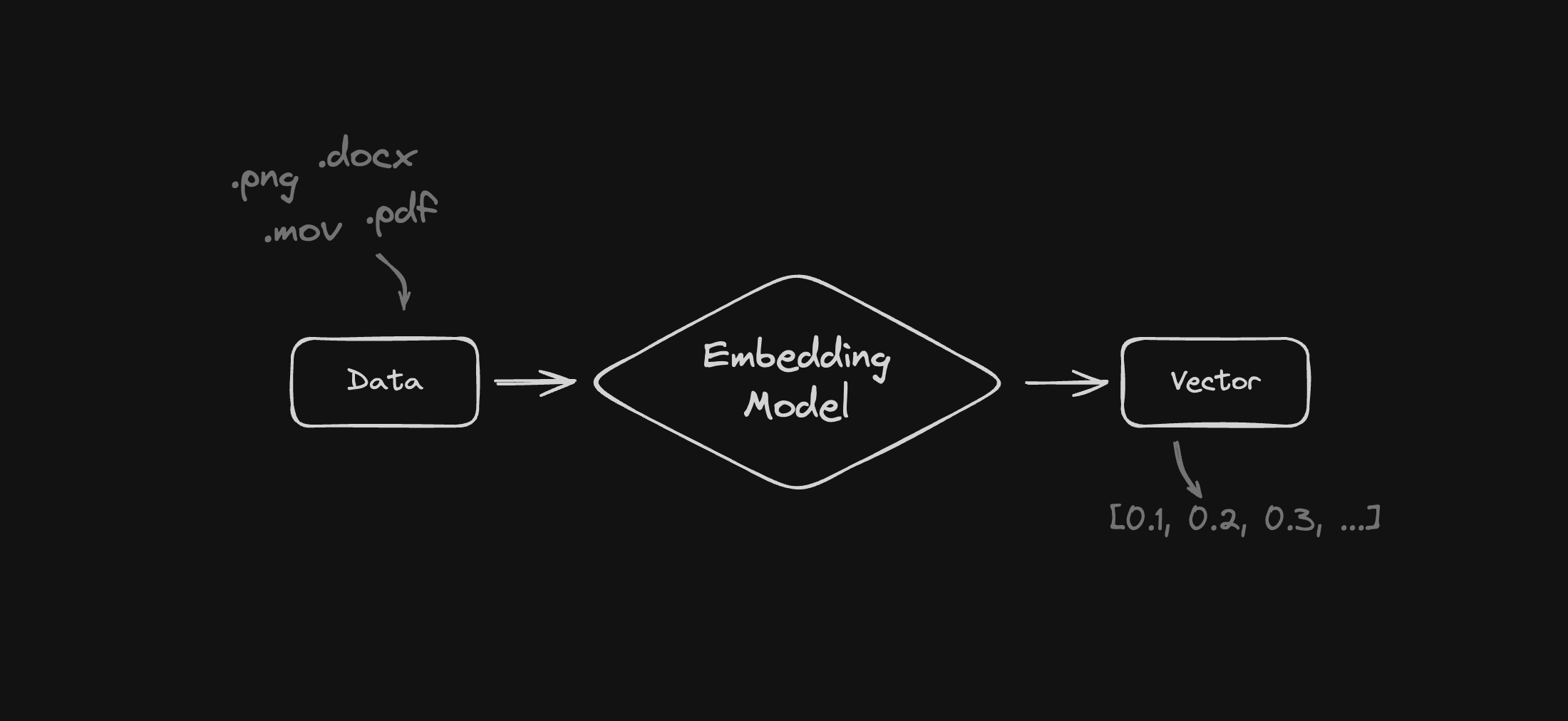
The above process is commonly used for user input. Whether the input is a query stored about data or data to be stored for future retrieval, the steps are essentially the same.
An image could be processed and transformed to a vector extracting details like if it's of a person, are they wearing glasses, is it raining, color, etc.
The specific embedding model will vary based on the type of data you’re processing, and this data can be stored in a database that supports storing high-dimensional space. Hugging Face is a popular community offering models and datasets that help reduce the cost and complexity of processing data.
#The importance of Indexing in Vector Databases
A vector database is also responsible for indexing the data it stores. Without indexing, finding similarities would be very difficult and expensive because it would require scanning through potentially billions of vectors linearly, resulting in slow query performance and high computational overhead for the database.
Indexing structures such as KD-Trees, Ball Trees, Hierarchical Navigable Small World (HNSW) Graphs, and Locality-Sensitive Hashing (LSH) sort vectors in a way that reduces the search space, allowing quick access of similar items by focusing searches on the most relevant parts of the dataset.
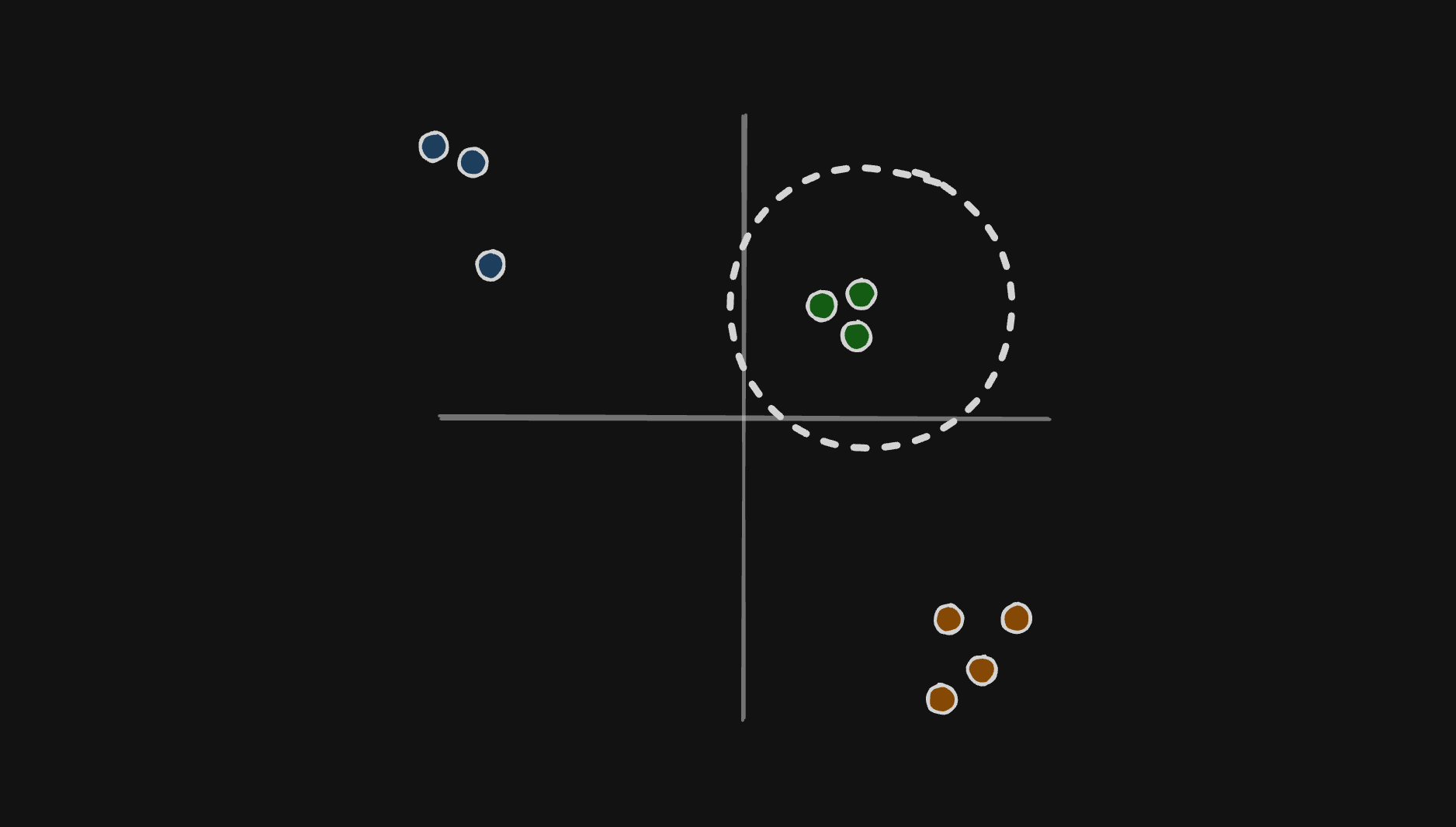
Turso uses a Graph-Based Index to achieve Approximate Nearest Neighbor, similar to HNSW, but is optimized for disk-based storage, DiskANN – we’ll learn more about the specifics of indexing in another post.
#Why would I use SQLite as my Vector Database?
LLMs process and handle transformations of data into vectors, but that’s it. The final embedding data (vectors) can be quite large depending on what you’re transforming. Now that Native Vector Search was just added to SQLite via Turso's Open Contribution fork — libSQL, that means you can store your embeddings in a SQLite file.
In libSQL, embeddings are just a column type — meaning there is zero setup and no extensions needed. When you insert a new row the index is updated automatically.
It also means you can query the table and embeddings using SQL, as well efficiently do approximate nearest neighbor search.
If you aren't interested in self hosting libSQL, Turso is a great turnkey option for using native vector search with SQLite. It works on all platforms, is extremely cost and resource efficient and is simple to get started. Just sign up for free and go.
And if you're already a Turso user you can now use the same database for vector embeddings, your user data, and everything else without managing and paying for multiple services.
Using Turso for vector embeddings also means you can take advantage of everything Turso has available, like embedded replicas for zero-latency queries, global availability with remote edge replicas, multitenant database options, backups, scale to zero, and more.
#Conclusion
Vector Databases and Embedding Models represent a significant improvement in the way we handle and search through vast amounts of unstructured data. By automating and improving the "tagging process" using trained models, a new world of possibilities for applications are now more accessible than ever before.
And now that you can opt to use the same managed SQLite offering you’re already familiar with as your Vector Database for Vector Similarity Search, rather than signing up for a separate, bespoke Vector Database and can opt to use the same managed SQLite offering they already are familiar with to do Vector Similarity Search, the barrier to entry into building your own compelling LLM solutions has lowered considerably.
Turso is free to get started and has vector support built-in. Get started today, and create your own vector database with indexing and similarity search.