
Generating and processing embeddings is a common task in AI-powered applications, but it can be computationally intensive. Imagine you're building a movie recommendation system that generates embeddings for movie descriptions. Processing these embeddings within your API or web application functions can lead to timeout issues when performed in real-time, especially in serverless environments.
In this post, we'll explore how to leverage Kafka to decouple data ingestion from processing, allowing your main application to remain responsive while handling large-scale embedding generation. You'll learn how to:
- Use Kafka to offload embedding generation to a background process
- Generate embeddings with Mixedbread's mxbai-embed-large-v1 model.
- Update a Turso database with the resulting embeddings
- Implement this architecture using libSQL, Redpanda Cloud (a Kafka-compatible streaming platform), and Mixedbread.
By the end of this tutorial, you'll have a system capable of processing embeddings asynchronously in a workflow that looks like this:
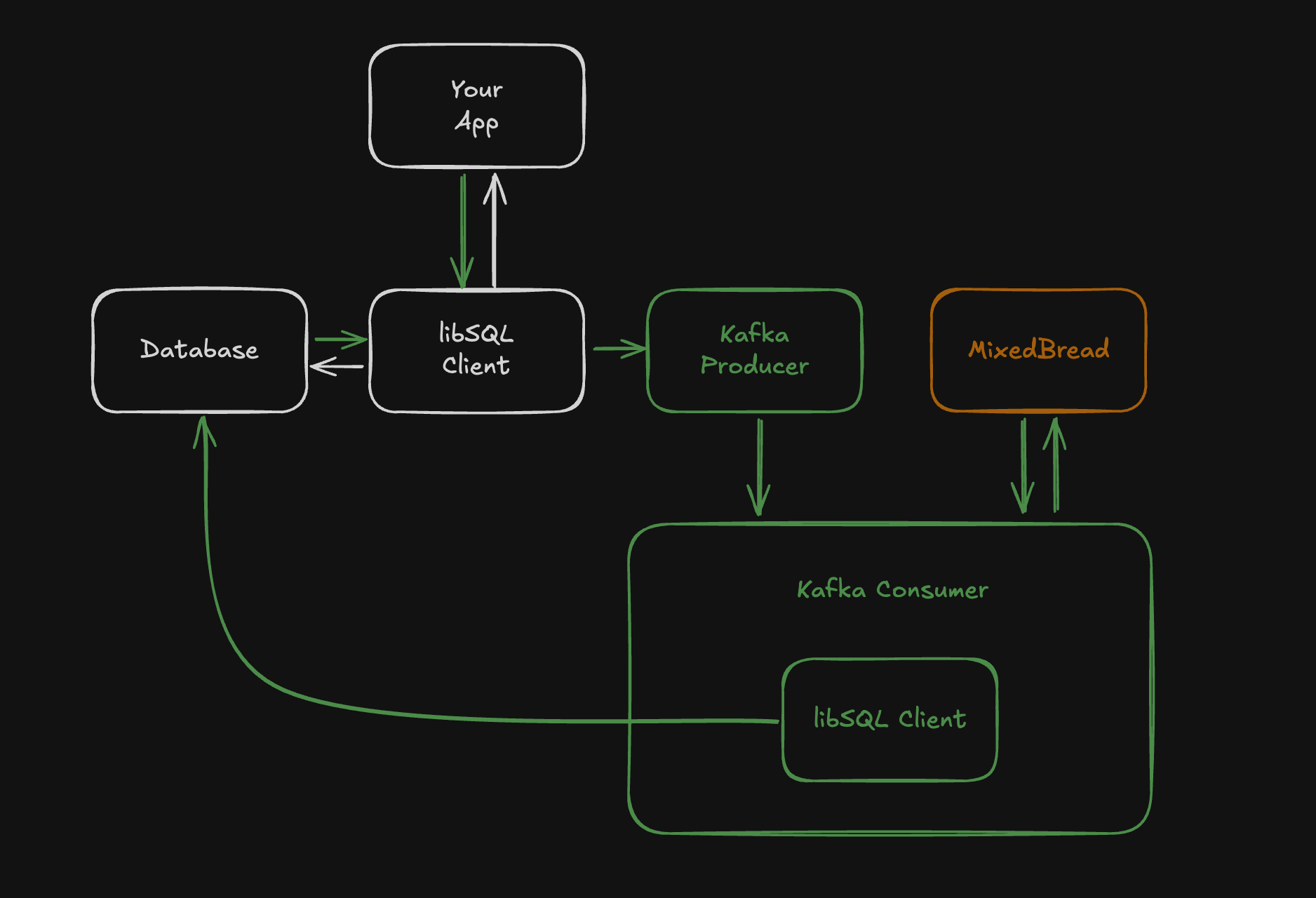
#Storing Vectors with Turso
Turso has native vector support, which means you can store and query embeddings directly in your existing Turso database... It's as easy as adding a new column!
Start by adding the libSQL client to your project:
npm install @libsql/client
Now imagine we have a database with the following schema:
CREATE TABLE movies (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
year INTEGER NOT NULL,
plot_summary TEXT,
genres TEXT,
embedding F32_BLOB(1024) -- Assuming 1024-dimensional embeddings
);
CREATE INDEX movies_embedding_idx ON movies(libsql_vector_idx(embedding));
You can recreate this schema in your own SQLite database by clicking the button below:
import { createClient } from '@libsql/client';
const client = createClient({
url: 'YOUR_LIBSQL_URL',
authToken: 'YOUR_AUTH_TOKEN',
});
#libSQL Middleware
While Turso is developing native Change Data Capture (CDC) support, we'll use a simple workaround with libSQL middleware to stream our data changes to Kafka.
Using libsql-middleware isn't necessary, since you can wrap your own try/catch around calls to the libSQL client, but it's super useful if you want to observe database calls in one place.
First, let's add the experimental middleware package to our project:
npm install libsql-middleware
We'll import the afterExecute hook, which allows us to access both the query and its result before sending data to Kafka. This strategy ensures we're only processing successful database operations, reducing unnecessary work and potential errors.
import { afterExecute, withMiddleware } from 'libsql-middleware';
const clientWithMiddleware = withMiddleware(client, []);
By using afterExecute, we gain several advantages:
- We can confirm that the data was successfully inserted or updated before processing
- We avoid generating embeddings for data that failed to insert due to validation constraints
- We have access to the full result of the query, which can be useful for complex operations
This middleware approach provides a robust foundation for our embedding generation pipeline, ensuring we're processing only the data we need, when we need it.
#Inserting data into libSQL
Now that we've set up the barebones of our middleware, let's look at how we can use it to insert data into our LibSQL database. The beauty of this approach is that the API remains unchanged from the standard @libsql/client usage, but now each operation is observed by our middleware.
Here's how we might insert a new movie into our database:
async function insertMovie(
title: string,
year: number,
plotSummary: string,
genres: string[],
) {
const query =
'INSERT INTO movies (title, year, plot_summary, genres) VALUES (?, ?, ?, ?)';
await clientWithMiddleware.execute({
sql: query,
args: [title, year, plotSummary, genres.join(',')],
});
}
await insertMovie(
'The Terminator',
1984,
"A human soldier is sent from 2029 to 1984 to stop an almost indestructible cyborg killing machine, sent from the same year, which has been programmed to execute a young woman whose unborn son is the key to humanity's future salvation.",
['Action', 'Sci-Fi'],
);
await insertMovie(
'Wall-E',
2008,
'In a distant, but not so unrealistic, future where mankind has abandoned earth because it has become covered with trash from products sold by the powerful multi-national Buy N Large corporation, WALL-E, a garbage collecting robot has been left to clean up the mess.',
['Animation', 'Adventure', 'Sci-Fi'],
);
In this example, clientWithMiddleware.execute() works exactly like the standard LibSQL client. The difference is happening behind the scenes — the middleware is observing each operation.
This approach gives us the best of both worlds:
- We maintain a clean, familiar API for database operations
- We automatically capture data changes for our embedding pipeline
- Our application remains unaware of the background processing, which we'll implement next
#Creating libSQL Middleware for Kafka
Now that we're capturing data changes, let's set up our streaming pipeline using Redpanda, a Kafka-compatible event streaming platform.
Redpanda allows us to decouple our data producers (the libSQL client) from our consumers (Mixedbread). This separation enables us to process data asynchronously and scale each component independently.
Make sure you create an account and cluster with Redpanda. Once you have your cluster, make sure to create a user:
Then give the user a name and select SCRAM-SHA-256 as the authentication mechanism:
Make sure to copy the username and password, as you'll need them when instantiating the kafkajs library.
For the purposes of this tutorial, click on the newly created user and Allow all operations in the ACL dialog:
Now from your Dashboard, copy the Server URL:

Now install the Node.js Kafka library:
npm install kafkajs
Now somewhere in your codebase, set up the Kafka producer:
import { Kafka } from 'kafkajs';
const redpanda = new Kafka({
brokers: ['...mpx.prd.cloud.redpanda.com:9092'], // <- from above
ssl: {},
sasl: {
mechanism: 'scram-sha-256',
username: '<username-from-above>',
password: '<password-from-above>',
},
});
const producer = redpanda.producer();
Next, we'll implement our sendToKafka function and wrap it with afterExecute we imported earlier. The afterExecute is executed after each database operation:
const sendToKafka = afterExecute(async (result, query) => {
try {
await producer.send({
topic: 'movie-insertions',
messages: [{ value: JSON.stringify({ result, query }) }],
});
} catch (error) {
console.error('Error sending to Kafka:', error);
}
return result;
});
You'll notice above we are producing events for the topic movie-insertions, but we haven't yet created it.
From the Redpanda Cloud Dashboard, create a new topic and give it the name movie-insertions:
Finally, we'll add this function to our middleware:
const clientWithMiddleware = withMiddleware(client, [sendToKafka]);
Every time insertMovie() is called, the query and its result will be automatically sent to our Kafka topic. This happens transparently to the rest of our application, maintaining a clean separation of concerns.
For example, when we insert a new movie:
await insertMovie(
'Inception',
2010,
'A thief who steals corporate secrets through the use of dream-sharing technology is given the inverse task of planting an idea into the mind of a CEO.',
['Action', 'Adventure', 'Sci-Fi'],
);
The movie data will be inserted into our LibSQL database and simultaneously sent to our Kafka topic for further processing. This sets the stage for Mixedbread to pick up the data and process it asynchronously.
#Process Kafka message and generate embeddings with Mixedbread
Now that our data is streaming smoothly through Kafka, it's time to set up a consumer to process these messages and generate embeddings using Mixedbread. Mixedbread offers state-of-the-art embedding and reranking models, including their open-source flagship model mixedbread-ai/mxbai-embed-large-v1.
What sets Mixedbread apart is that their open-source models are specifically trained to work optimally with embedding optimization methods like binary/int8 embedding quantization, matryoshka or the combination of both. This specialized training ensures that when embeddings are compressed using these techniques, they retain maximum performance. This makes vector search highly efficient and scalable, enabling embeddings-based applications—like our movie recommendation system—that are both cost-effective and powerful. Let's explore how we can leverage these models in our project. To learn more about embeddings check out Mixedbread's blog
Mixedbread's models are available on Hugging Face and thus usable via the @xenova/transformers library, alternatively you can also use their API directly.
First, let's install the transformers.js library:
npm install @xenova/transformers
Now, let's set up our Kafka consumer and embedding model:
import { Kafka } from 'kafkajs';
import { pipeline } from '@xenova/transformers';
const redpanda = new Kafka({
brokers: ['...mpx.prd.cloud.redpanda.com:9092'], // <- from above
ssl: {},
sasl: {
mechanism: 'scram-sha-256',
username: '<username-from-above>',
password: '<password-from-above>',
},
});
const consumer = redpanda.consumer();
async function processMessages() {
await consumer.connect();
await consumer.subscribe({ topic: 'movie-insertions', fromBeginning: true });
// Create a feature extraction pipeline
const model = await pipeline(
'feature-extraction',
'mixedbread-ai/mxbai-embed-large-v1',
);
await consumer.run({
eachMessage: async ({ message }) => {
const movie = JSON.parse(message.value.toString());
const textForEmbedding = `${movie.title} ${movie.plot_summary} ${movie.genres}`;
// Generate embedding
const output = await model([textForEmbedding], {
pooling: 'cls',
normalize: true,
});
const embedding = output.tolist()[0];
await updateMovieEmbedding(movie.id, embedding);
},
});
}
processMessages().catch(console.error);
In the code above, we're using the open-source model mixedbread-ai/mxbai-embed-large-v1 via the @xenova/transformers library to generate embeddings for our movie data. The small size of the model offers a great balance between performance and efficiency, and since it's open source we can run it locally without relying on external APIs, which can be beneficial for privacy and latency. The extractor pipeline processes the movie's combined text and produces a normalized embedding vector.
You'll notice we call updateMovieEmbedding(), but we haven't yet created that function; we'll do that next.
#Storing Embeddings in Turso
Now that we're generating embeddings for our movies, we need to store them in our database for quick retrieval and similarity searches. We'll use Turso, which has native vector support, making it an ideal choice for storing and querying embeddings.
Let's create a function to update our movie records with their newly generated embeddings:
import { createClient } from '@libsql/client';
const client = createClient({
url: 'LIBSQL_URL',
authToken: 'LIBSQL_AUTH_TOKEN',
});
async function updateMovieEmbedding(movieId: number, embedding: number[]) {
const query = 'UPDATE movies SET embedding = vector32(?) WHERE id = ?';
await client.execute(query, [JSON.stringify(embedding), movieId]);
}
This function takes a movie ID and its corresponding embedding, then updates the movie record in our Turso database. We're storing the embedding as a JSON string, which Turso can efficiently index and query.
With this setup, every time a new movie is inserted into our database:
- Kafka sends a message to our consumer
- We generate an embedding for the movie title using Mixedbread
- We update the movie record in Turso with the new embedding
#Retrieving Movie Recommendations
Now that we have our movies stored with embeddings, let's implement a function to retrieve movie recommendations based on a user's query. We'll use Turso's vector similarity search capabilities along with Mixedbread and transformers.js to generate embeddings for the user's query.
import { createClient } from '@libsql/client';
import { MixedbreadAIClient } from '@Mixedbread-ai/sdk';
const client = createClient({
url: 'LIBSQL_URL',
authToken: 'LIBSQL_AUTH_TOKEN',
});
async function getMovieRecommendations(
query: string,
topK: number = 5,
): Promise<any[]> {
const queryEmbedding = await generateEmbedding(query);
// Perform vector similarity search
const sql = `
SELECT movies.id, movies.title, movies.year, movies.genres
FROM vector_top_k('movies_embedding_idx', vector32(?), ?) AS v
JOIN movies ON movies.id = v.id
ORDER BY v.distance
`;
try {
const result = await client.execute({
sql,
args: [JSON.stringify(queryEmbedding), topK],
});
return result.rows;
} catch (error) {
throw error;
}
}
async function generateEmbedding(text: string): Promise<number[]> {
const model = await pipeline(
'feature-extraction',
'mixedbread-ai/mxbai-embed-large-v1',
);
const output = await model([text], { pooling: 'cls', normalize: true });
return output.tolist()[0];
}
This getMovieRecommendations function does the following:
- It takes a user's query and generates an embedding using Mixedbread.
- It uses Turso's
vector_top_kfunction to perform an efficient similarity search on the indexed embeddings. - It joins the results with the
moviestable to retrieve the movie details. - It returns the top K most similar movies.
You can use this function in your application like this:
async function recommendMovies(userQuery: string) {
const recommendations = await getMovieRecommendations(userQuery, 5);
// Process recommendations (e.g., send to frontend)
}
recommendMovies("I'm in the mood for a sci-fi action movie with robots");
#Conclusion
In this article, we've explored an efficient architecture for processing embeddings asynchronously using libSQL, Redpanda Kafka, and Mixedbread.
We've learned how to:
- Capture and stream database changes using libSQL middleware and Kafka
- Generate high-quality embeddings with Mixedbread
- Store and query vector embeddings efficiently with Turso
- Implement a recommendation system using Vector Similarity Search using Turso's native vector support
Redpanda and Mixedbread are both easy to integrate and scale, making them both an excellent choice for generating embeddings in production environments.
This architecture is a simple workaround until we have a more robust solution for CDC, but it's a great starting point. Please join us on Discord to discuss this article, your project, and CDC requirements.