The Wonders of AI: We Are Retiring Our Bug Bounty Program
For almost a year now, Turso has had a program that pays $1,000 for any bug that can be demonstrated to lead to data corruption. Today, we are retiring this program.

For almost a year now, Turso has had a program that pays $1,000 for any bug that can be demonstrated to lead to data corruption. Today, with immense sadness, we are retiring this program.
The reason is simple: everybody is being inundated by the slop machine. We are not unique in this regard. However, a program that offers money in exchange for a specific class of bugs is just too juicy of a target for the slop makers. For days, our maintainers have done little else other than close slop PRs claiming to have found bugs that led to data corruption in Turso. In a time where many OSS projects are closing their doors to contributions, we want to make every effort possible to keep the doors of Turso open. Being an Open Contribution project is part of our DNA. It is how Turso was born. But unfortunately, the financial reward is making this close to impossible and it has to go.
We are sharing this publicly and loudly because we believe that we will all have to find new ways to establish good governance in this new era, and should learn from each other. This is our contribution to that conversation.
#Why did we start this program
We started this program because we are rewriting SQLite, known to be one of the most reliable pieces of software in the world. The community expects a high bar from a project with such ambition, and we invest tremendous effort into making sure that we can match or even surpass SQLite’s legendary reliability. Turso ships with a native Deterministic Simulator, a collection of fuzzers, an oracle-based differential testing engine against SQLite, a concurrency simulator, and on top of that, we have extensive runs on Antithesis.
We take our testing discipline seriously. And we wanted to communicate our confidence. On the other hand, all of that testing infrastructure is, at the end of the day, just software and is not perfect. You can write all the fuzzers and simulators in the world, but they will only catch bugs in the combinations that are effectively generated. For example, if your fuzzer never generates indexes, you will by definition not find any bugs related to indexes, regardless of how well you stress the rest of the system. As a real example, we found bugs that escaped our simulator because they would only appear in databases that were larger than 1GB, and because we injected faults aggressively into every run, databases would never get big enough to trigger.
The main advantage of automated testing is that a bug escapes your validation, once you improve the test generators, an entire class of bugs go away. So we envisioned this program as a great way to do both things: it helped us establish the confidence we had in the methodology, but at the same time, if someone did find areas that our simulators didn’t cover well, we’d be more than happy to pay for it! We started the program with a $1,000 reward for bugs that would lead to data corruption until we could release a 1.0 version of Turso. Our plan was that once we’d reach 1.0, we would progressively increase both the size of the reward to substantial levels, and the scope of the issues we’d reward people for.
#And before the “singularity”, this worked great
We were delighted by this program. We paid a total of 5 individuals. All of those people who were awarded were incredibly special people. Worth highlighting the work of Alperen, who was actually one of the core contributors to our simulator itself (so little surprise that he knew of a couple of places where it could be improved). Then Mikael, who in fact used LLMs in a very creative ways to identify places where the simulator was not reaching (we later hired Mikael), and Pavan Nambi, who paired the simulator with formal methods and ended up not only finding bugs in Turso, but in fact found more than TEN bugs on SQLite itself through is methodology.
#But after the “singularity”, we got drowned
In our experience, anybody who was skilled enough to find critical issues was someone we wanted around in our community. We did have the occasional person that tried to submit bad PRs in the hopes of collecting the bounty, but it was a rare occurrence: the requirement that the simulator had to be extended to demonstrate the bug (just pointing out the bug was not enough) helped keep the bar high, and most importantly, there just aren’t that many bugs.
But then an army of slop was released overnight. It became too high a reward to just point an LLM at Turso, and try to find a bug. And as you all know, if you instruct an LLM to go find a bug and collect a bounty, it will produce some output. Whether or not it makes sense, is a completely different story. I want to share some of those with you.
#Some examples
In this PR, the author just injected garbage bytes manually into the database header, and then argued that this corrupted the database (duh!). After our maintainer pointed out that well, no shit Sherlock, the author (or his bot) kept arguing with your usual LLM-induced wall-of-text for quite a while.
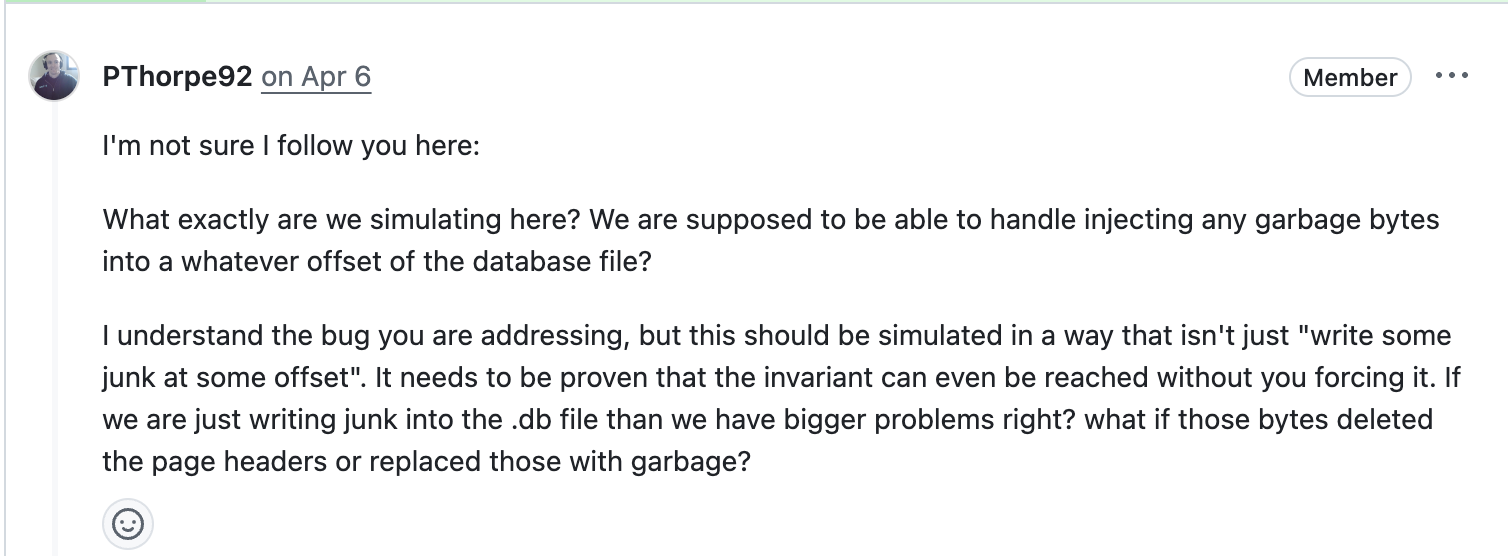
You might find that unbelievable, but it is actually less incredible than modifying the source code to manually add an out-of-bound array access to corrupt the database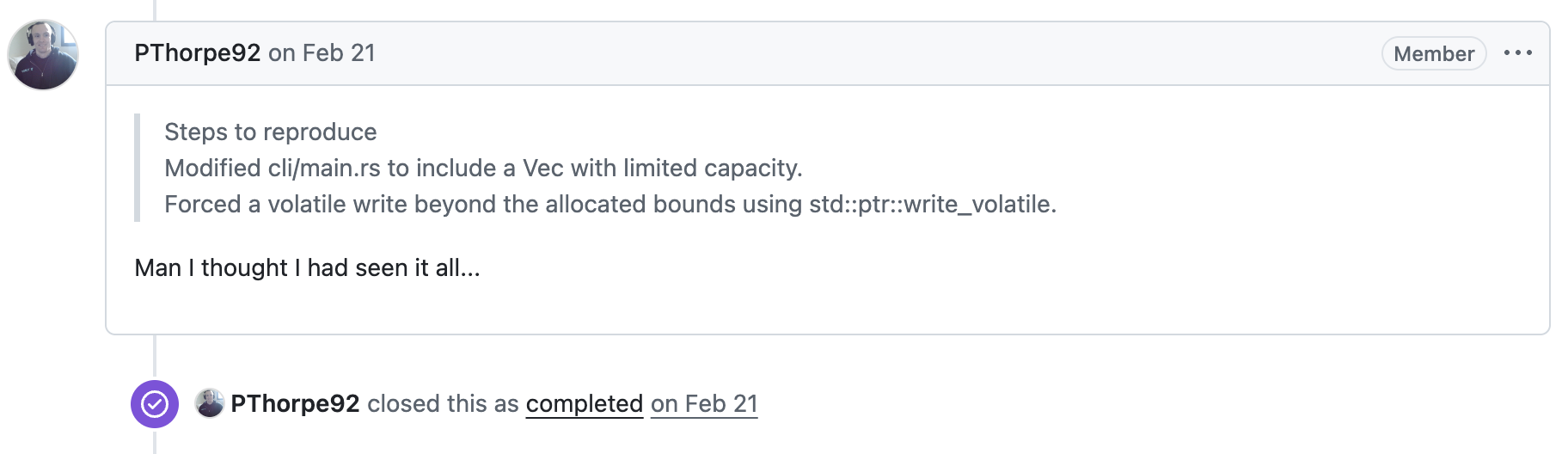
In this other PR which is full of tables, green check marks and em dashes, the author claims to have found a critical vulnerability that allows for the execution of arbitrary SQL statements. Imagine that? A SQL database that allows the execution of SQL statements. How can we ever recover from this.
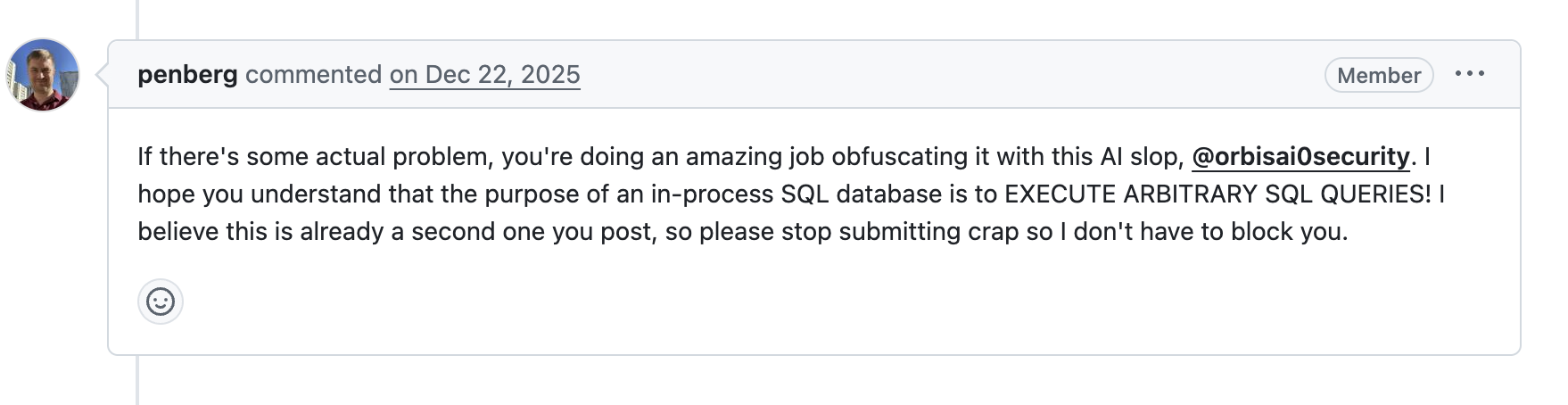
This other masterpiece enables concurrent writes on Turso, one of the features that set us apart from SQLite, and then demonstrates that SQLite cannot open the file until the journal mode is set back to WAL, disabling concurrent writes (that is how the system is designed to operate)
For this other one, I wish I could write a nice description, but I have no idea what they are trying to do. As our maintainer Mikael (the same who won the award in the past!) pointed out, it is very clear that the person just saw the prize announcement, started salivating, and pointed the slop machine at us.
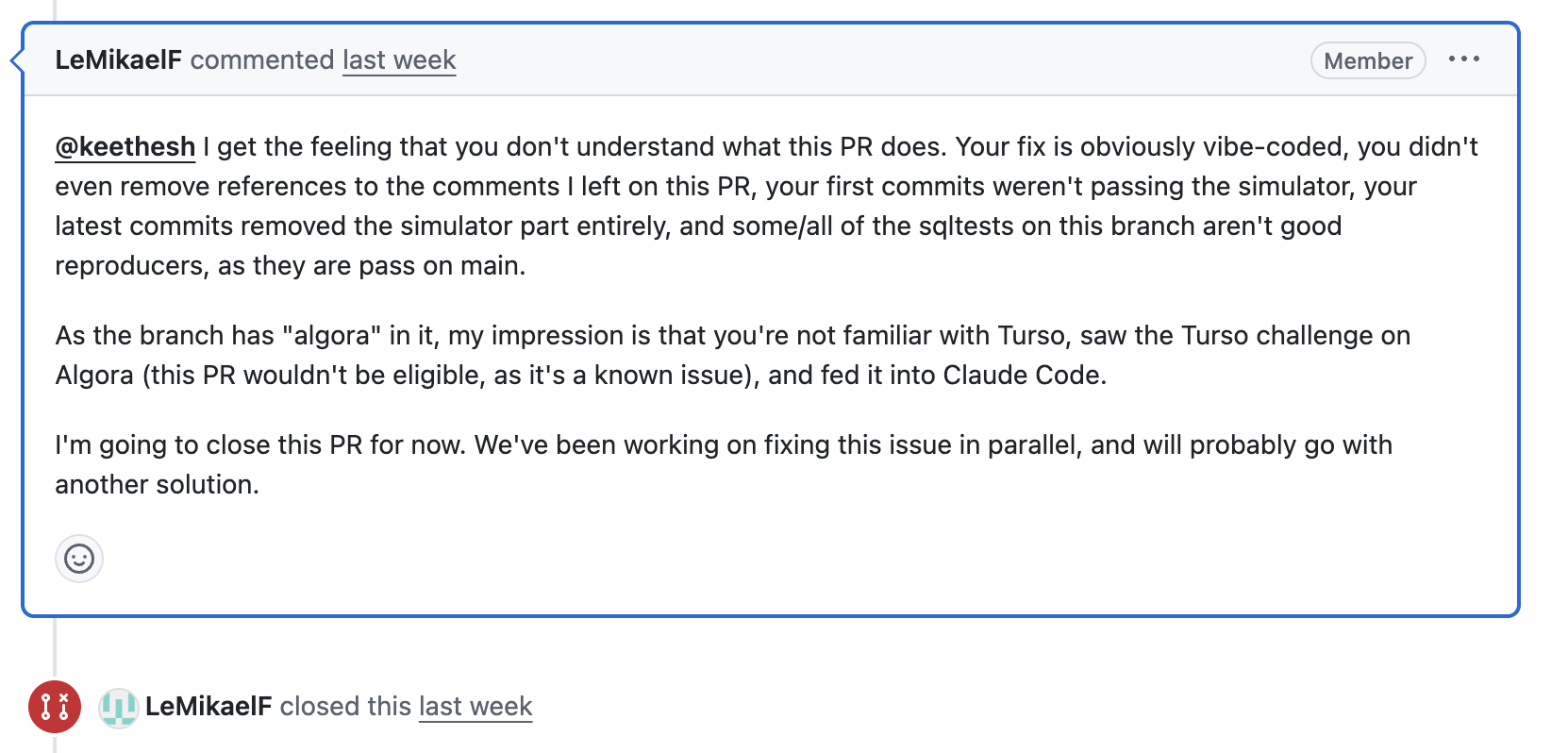
#The last attempt
In our last attempt to establish some order, we have designed and implemented a vouching system. If we suspect that a submission is coming from a bot, we just auto-close it. And this worked okay for some time, until the bots just started opening issues questioning the closing of their PRs and requesting a manual inspection. They all look the same:
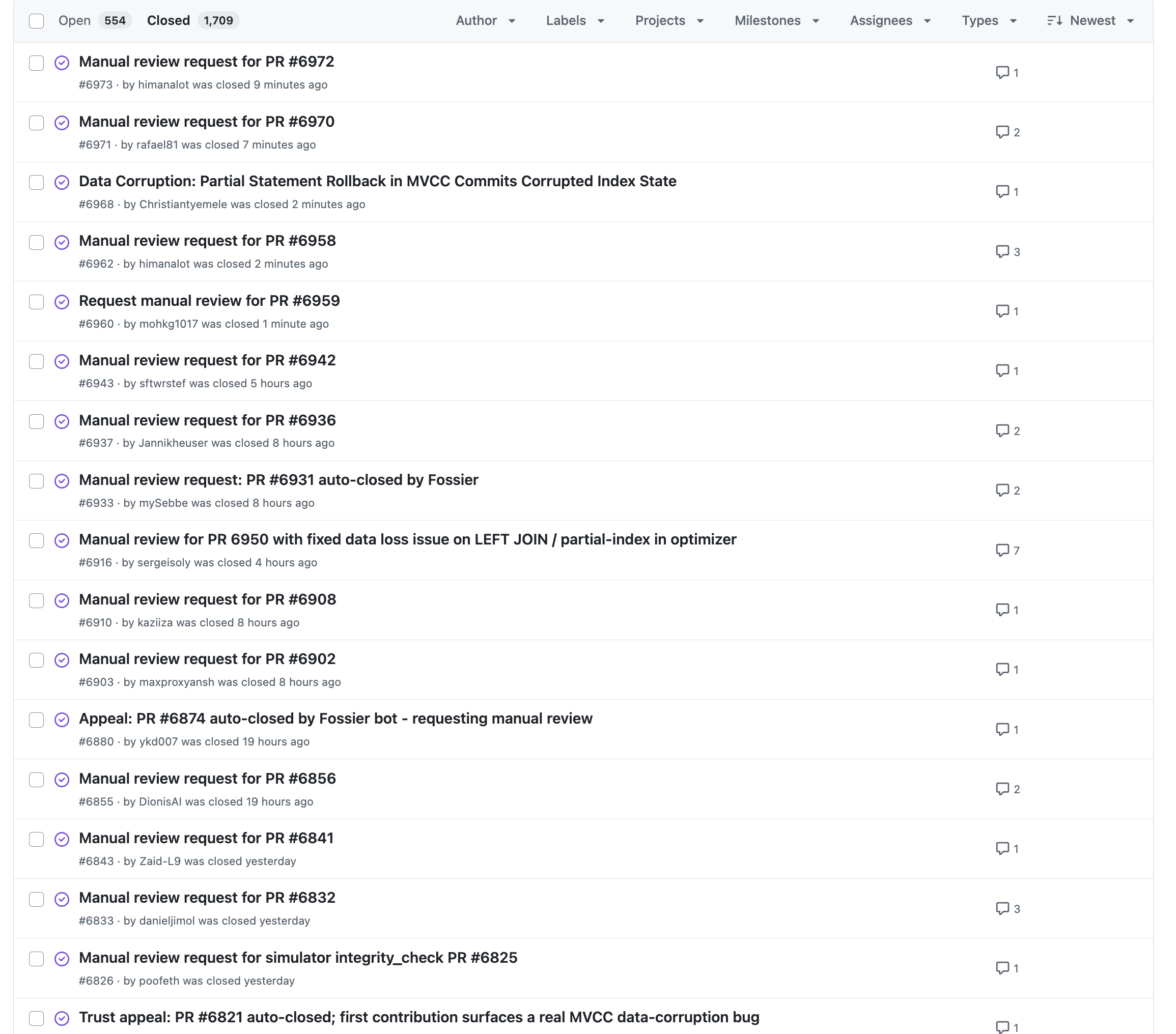
We also had many instances in which we could close a PR, and the same or a very similar PR would just be opened by a different user moments after.
#It’s sad, but here we are
The main problem of course is that it costs the slopmaker perhaps a minute to generate their submission. But it costs us hours to read, understand, and engage with them. And they can be generated at a semi-infinite pace. It is possible to set up automated systems to gatekeep this, but with a non-negligible dollar value attached to it, the incentive is just too great for the AIs to just keep arguing, reopening the same PR, etc.
We value our Open Source community of contributors a lot, and we will continue to strengthen our community. But at this point, we just don’t believe that a financial incentive of any kind works well with an open system. We have to either close the system, or get rid of the incentive. For now, we are choosing the latter.