Speeding up a Remix website with Turso's embedded replicas hosted on Akamai's Linode
Using Turso's embedded replicas to speed up a Remix website hosted on Akamai's Linode
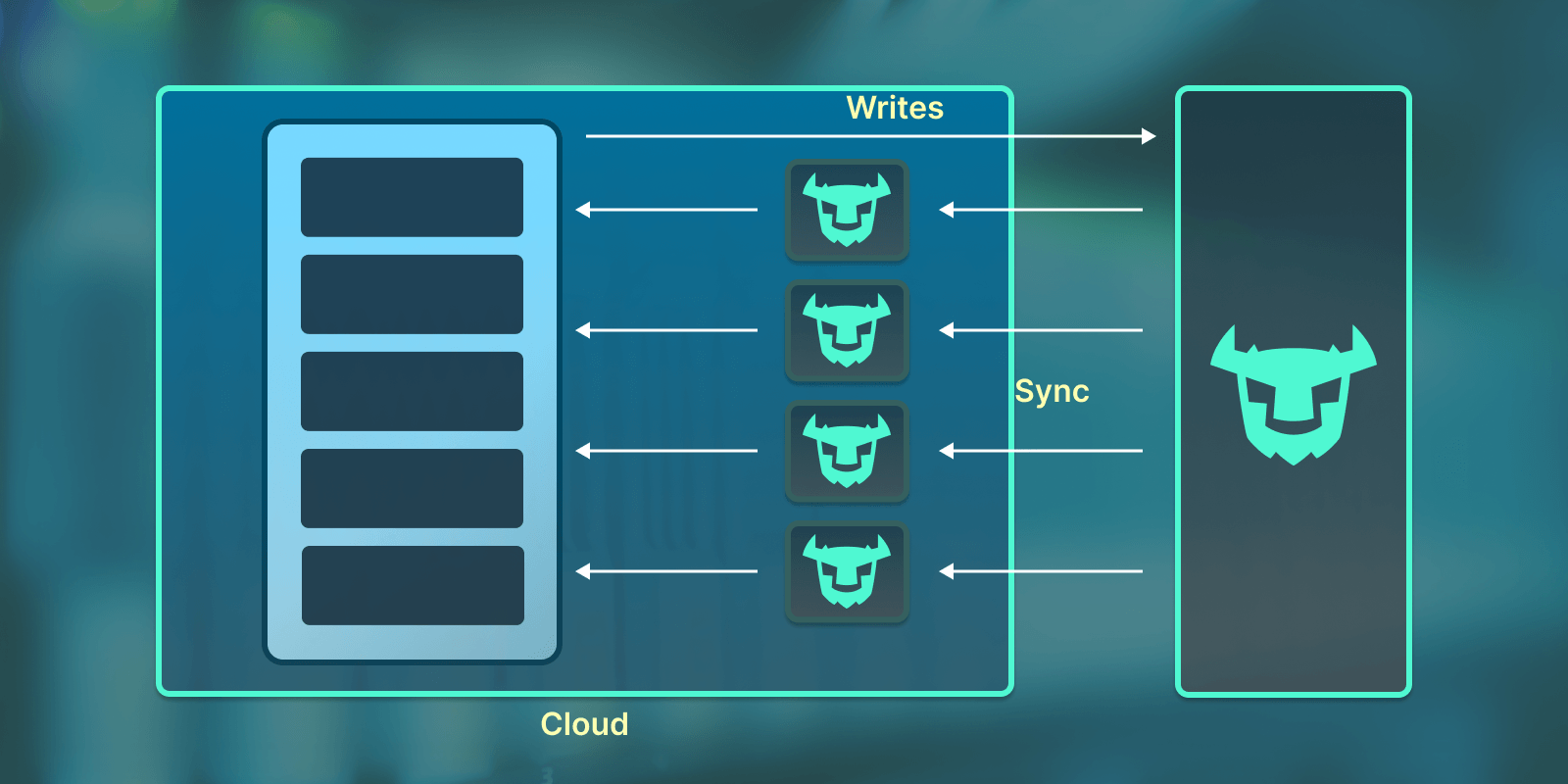
This post references an older version of Turso.
Turso is a full, ground-up rewrite of SQLite. Turso Cloud lets you query your databases over the wire or sync them to and from your own devices and servers — with full offline support. Because Turso databases are files — not processes — they never sleep, never cold-start, and don't need scale-to-zero. There is no longer any concept of “edge replication,” and the legacy libSQL SDKs have been replaced by new Turso-native SDKs.
To learn more about Turso today, visit turso.tech or read the documentation.